Le rapport « The 2028 Global Intelligence Crisis » tire la sonnette d'alarme sur la menace imminente que représente l'IA pour les emplois de bureau, prédisant que l'IA mènera à un avenir apocalyptique
Un rapport apocalyptique sur l'IA devient viral après avoir averti que l'importance de l'intelligence humaine allait « s'estomper ». « Tout au long de l'histoire économique moderne, l'intelligence humaine a été une ressource rare », écrit Citrini Research dans son rapport. « Nous assistons aujourd'hui...
Anthropic lance Remote Control pour Claude Code en aperçu de recherche, qui vous permet désormais de poursuivre une session de développement local depuis votre téléphone, votre tablette ou votre navigateur
Anthropic a lancé Remote Control pour Claude Code. Les utilisateurs peuvent désormais poursuivre une session de développement local depuis leur téléphone, leur tablette ou leur navigateur. Cette fonctionnalité est disponible en avant-première pour les abonnés Pro et Max. Une session Claude Code...
Inception lance Mercury 2, le LLM à raisonnement le plus rapide, qui serait 5 fois plus rapide que les principaux LLM optimisés pour la vitesse, avec un coût d'inférence réduit
Alors que l'industrie de l'IA dépense des milliards pour gagner quelques fractions de seconde sur les modèles autorégressifs jeton par jeton, la génération basée sur la diffusion d'Inception est une avancée architecturale qui rend le raisonnement à haut débit natif au modèle. Fondée par des chercheurs de Stanford, UCLA et...
La bulle IA commence à se dégonfler, OpenAI réajuste ses prévisions de dépenses, de 1 400 milliards à 600 milliards de $, tout en perdant des milliards chaque mois
OpenAI a revu à la baisse ses ambitions en matière de dépenses informatiques à long terme, alors que des signes indiquent que le boom de l'intelligence artificielle (IA) entre dans une phase plus modérée. L'entreprise prévoit désormais de dépenser environ 600 milliards de dollars en capacité de calcul d'ici 2030, soit bien moins que les...
Apple annonce le déploiement mondial de nouveaux outils de vérification de l'âge sur toutes ses plateformes, conçus pour aider les développeurs à se conformer à un réseau croissant de lois sur la sécurité des enfants
Apple a annoncé le déploiement mondial de nouveaux outils de vérification de l'âge sur l'ensemble de ses plateformes, afin de répondre au renforcement des réglementations en matière de sécurité des enfants. Cette mise à jour améliore l'API « Declared Age Range », qui permet aux applications...
Micron annonce sa mémoire GDDR7 de nouvelle génération, qui promet une capacité accrue et une bande passante nettement supérieure aux solutions actuelles. Dans son dernier article de blog, le fabricant a dévoilé des modules de 24 Go atteignant des vitesses de 36 Gbit/s. Selon l'entreprise, cette solution est conçue pour les jeux modernes et les exigences croissantes de l'intelligence artificielle. L'une des premières cartes graphiques à utiliser la GDDR7 fut la GeForce RTX 5090. Actuellement, les versions GDDR7 les plus rapides disponibles atteignent environ 30 Gb/s, mais Micron a annoncé une augmentation à 36 Gb/s, soit environ 20 % plus rapide que les chipsets haut de gamme actuels. Les nouvelles puces devraient augmenter la capacité mémoire totale des cartes graphiques jusqu'à 50 % par rapport aux configurations précédentes. Concrètement, cela permettra de concevoir des modèles avec une mémoire tampon VRAM plus importante, ce qui est particulièrement crucial pour les hautes résolutions et les effets graphiques avancés. Avec un débit de 36 Gb/s et un bus mémoire large, il sera possible d'atteindre des vitesses de transfert de données très élevées. Selon la configuration, on parle d'un débit dépassant les 2 To/s pour les versions les plus performantes. Un tel niveau était, il y a encore quelques années, réservé aux accélérateurs de calcul les plus onéreux.
Micron souligne que l'augmentation de la capacité mémoire et de la bande passante se traduit directement par une meilleure qualité de jeu. Les jeux modernes utilisent des textures de plus en plus complexes, des mondes immenses et des techniques comme le lancer de rayons. De plus, des algorithmes de mise à l'échelle d'image et de génération d'images sont intégrés. Selon le fabricant, la GDDR7 est conçue pour contribuer à maintenir une fluidité stable aux résolutions 4K, 5K et même 8K, même dans les scènes à forte charge. Les nouvelles mémoires ont également des implications pour les applications liées à l'IA. De plus en plus de cartes graphiques sont utilisées non seulement pour les jeux, mais aussi pour les modèles génératifs, le traitement d'images et de vidéos, ainsi que pour les tâches de calcul. Un débit plus élevé se traduit par un traitement des données plus rapide par les modèles d'IA, tandis qu'une capacité accrue permet de gérer des réseaux plus complexes sans nécessiter de transferts de données fréquents. Micron souligne également une efficacité énergétique améliorée grâce à des modifications architecturales et à des tensions de fonctionnement plus basses.
D'autres fabricants travaillent également au développement de la GDDR7, notamment Samsung Electronics, qui a déjà lancé la production en série de ces modules et promet des vitesses encore plus élevées à l'avenir. Parallèlement, les nouvelles générations de puces graphiques, y compris les modèles à venir de NVIDIA, devraient exploiter pleinement le potentiel d'une mémoire plus rapide et plus volumineuse. (Lire la suite)
Après plusieurs années de stagnation, le projet LibreOffice Online est de nouveau au cœur des préoccupations de la Document Foundation. L'organisation a annoncé la reprise du développement d'une version en ligne de la suite bureautique, qui vise à offrir une alternative libre et gratuite aux services cloud dominants sur le marché. LibreOffice Online a été créé comme outil de collaboration pour la création de documents texte, de feuilles de calcul et de présentations directement dans un navigateur. Lancé en mars 2015, le projet était initialement présenté comme la réponse de la communauté open source à la popularité croissante de Google Docs et de Microsoft 365. Sa principale différence réside dans son modèle de distribution : absence de frais de licence et accès intégral au code source. LibreOffice Online repose sur une architecture client-serveur. Un simple navigateur web moderne suffit aux utilisateurs pour accéder aux documents. Tout le traitement est effectué côté serveur et l'interface s'affiche dans une fenêtre de navigateur, quel que soit le système d'exploitation ou l'appareil utilisé. La Fondation n'envisage pas de lancer une instance centrale et publique, à l'instar des services cloud commerciaux. Elle encourage plutôt les organisations et les utilisateurs individuels à déployer la solution sur leur propre infrastructure. Ce modèle est en accord avec sa philosophie de décentralisation et de contrôle des données.
En parallèle, une version classique de LibreOffice, installée localement, est développée et fonctionne depuis des années comme alternative gratuite aux suites bureautiques commerciales. Ce projet, dérivé du code source d'Apache OpenOffice, demeure l'une des plus importantes initiatives open source du secteur des logiciels bureautiques. Bien que l'annonce officielle de la suspension des travaux sur LibreOffice Online ait été faite en 2022, les derniers changements significatifs apportés au dépôt remontent à 2020. À cette époque, le projet a fait l'objet d'un changement d'image et a été fortement associé à Collabora, qui a joué un rôle technologique de premier plan. La même année, Collabora s'est concentrée sur sa propre version du projet, Collabora Online. Cette solution a commencé à fonctionner comme un service distinct, développé commercialement, avec son propre cycle de publication et son propre support technique. La décision de fermer LibreOffice Online a été prise suite à un vote du conseil d'administration de la fondation. Le motif officiel invoqué était un conflit d'intérêts. Des représentants de Collabora, dont Michael Meeks, siégeaient au conseil. Des liens personnels et le développement parallèle de projets connexes ont engendré des tensions au sein de la communauté.
La fondation affirme actuellement que les obstacles organisationnels ont été levés et qu'il n'existe aucun frein formel à la reprise du projet. Cependant, aucun détail concernant d'éventuels changements structurels n'a été fourni. Michael Meeks remet ouvertement en question la pertinence de cette relance. Il estime que la plupart des développeurs actifs qui travaillaient auparavant sur LibreOffice Online œuvrent depuis longtemps sur Collabora Online. Il craint que le développement parallèle de deux projets similaires n'entraîne une fragmentation des ressources et une concurrence accrue pour les mêmes contributeurs. Les données relatives aux contributions au code illustrent l'ampleur des dépendances. Environ 95 % du code de Collabora Online a été développé par l'équipe Collabora et ses partenaires. Fin 2025, l'entreprise était responsable de 45 % des modifications apportées au dépôt principal de LibreOffice hors ligne. Collabora développe également sa propre solution de bureau, Collabora Office, qui a fait l'objet d'une mise à jour importante en novembre 2025. (Lire la suite)
Apple s'apprête à lancer cet automne des MacBook Pro dotés d'écrans OLED et de commandes tactiles, intégrant la fonctionnalité Dynamic Island, similaire à celle de l'iPhone. Pour rappel, Dynamic Island est apparue pour la première fois sur les iPhone 14 Pro et iPhone 14 Pro Max, avec une encoche ovale affichant les notifications et les informations système. Sur le MacBook Pro, cet élément sera plus petit que sur les iPhone actuels. Les nouveaux MacBook Pro seront disponibles avec des écrans de 14 et 16 pouces et conserveront globalement un design proche de la génération actuelle. Cependant, Apple repensera l'interface macOS, la rendant plus dynamique et mieux adaptée à une utilisation tactile comme à la disposition classique avec curseur.
D'après une source interne, lorsqu'on appuie sur un bouton ou une commande, le système affiche un menu supplémentaire proposant des options plus pertinentes pour les commandes tactiles. Il est important de noter qu'Apple a longtemps refusé d'intégrer des écrans tactiles à ses ordinateurs Mac. En octobre 2010, quelques mois après la sortie du premier iPad, Steve Jobs déclarait que les surfaces tactiles verticales étaient inconfortables et qu'un Mac tactile serait « ergonomiquement catastrophique ». Or, Apple promeut désormais activement l'iPad non seulement comme une tablette tactile, mais aussi comme un ordinateur portable de remplacement lorsqu'un clavier y est connecté. Ainsi, la position de la direction d'Apple sur ce sujet a clairement évolué, à l'instar du marché de l'électronique depuis 2010. (Lire la suite)
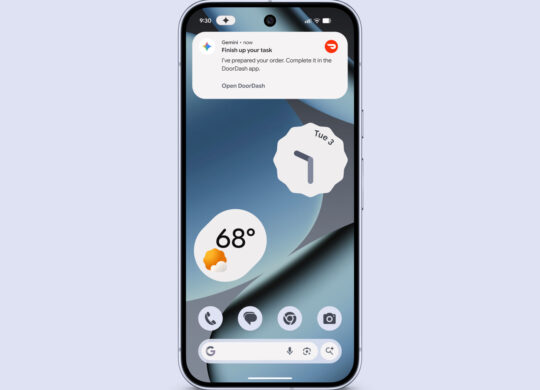
Google a franchi une étape dans l’évolution de son intelligence artificielle Gemini avec de nouvelles capacités agentiques, ce qui permet d’accomplir des tâches complexes en toute autonomie sur les smartphones Android. Un assistant IA qui clique à votre place L’annonce marque un tournant stratégique pour Android. Google ne …
C’est une étape majeure dans l’histoire du web open source. Meta vient de transférer officiellement React à la Linux Foundation, qui annonce la création de la React Foundation lors de son Member Summit à Napa, en Californie. Le projet passe […]
C’est un geste rare dans le monde du renseignement : l’Australian Signals Directorate (ASD) vient de rendre public Azul, sa plateforme interne d’analyse de malwares. L’outil est désormais disponible sur le GitHub de l’Australian Cyber Security Centre sous licence MIT, […]
À mesure que les écosystèmes numériques se développent, la souveraineté des données s’impose comme un facteur critique dans la manière dont les infrastructures sont conçues et gouvernées. Pour les entreprises, le défi consiste à trouver le juste équilibre : les […]
Jetpack Cat cartonne, mais son agressivité va être réduite pour relancer sa présence en compétitif. Dans le même temps, Blizzard assume des héros plus atypiques et un rythme soutenu.
Overwatch : cadence d’un héros tous les 2 mois et place aux profils atypiques
Avec le rebranding d’Overwatch 2 en Overwatch, Blizzard a annoncé une série de nouveaux héros dès la première saison de cette nouvelle ère. Alec Dawson, associate director, explique que la popularité de Jetpack Cat et d’autres personnages non conventionnels encourage l’équipe à explorer davantage de héros « oddball ».
Objectif affiché : un nouveau héros chaque saison sur la première année, soit un ajout tous les deux mois, tant que c’est soutenable et hors événements majeurs de gameplay. Ce rythme offre, selon Dawson, plus d’occasions de tenter des approches de gameplay et des rôles différenciants pour élargir l’éventail de styles jouables.
Jetpack Cat : la plus bannie, nerf ciblé à venir
Dans un échange avec PCGamesN, Dawson indique que Jetpack Cat est actuellement la héroïne la plus bannie. Blizzard veut corriger le tir pour la rendre plus jouable en compétitif, en « calmant un peu son agressivité ».
Le nerf visera sa capacité à plonger les backlines, surtout lorsque ses perks Claws Out (mineur) et Territorial (majeur) se cumulent et en font une menace capable de prendre des 1v1. L’équipe va « réduire un peu » cette synergie et observer l’impact. Le système de bans sert de guide pour ajuster l’équilibrage, un point clé avec la cadence d’ajouts accélérée.
Blizzard montre aussi qu’il écoute les retours sur le design des héros, comme l’illustre la révision prévue d’Anran après des critiques sur son aspect jugé trop générique.
Si la cadence bimestrielle tient, l’équilibrage deviendra un chantier continu, soutenu par les données de bans et la réception communautaire. La marge de manœuvre pour des profils « oddball » pourrait dynamiser la méta, à condition de contenir les excès de kits trop polarisants comme celui de Jetpack Cat.
Six mois sans mise à jour, puis un correctif tombe et rebats les cartes pour la ROG Ally. Bonne nouvelle pour les joueurs, mais le signal reste brouillé côté support global.
AMD Ryzen Z1 Extreme : retour des mises à jour sur ROG Ally
ASUS déploie un nouveau package pilote pour sa ROG Ally, alors que la console était figée sur des pilotes SoC datant d’août 2025. Le SoC AMD Ryzen Z1 Extreme, annoncé avec un cTDP configurable de 9 à 30 W, impose des validations OEM spécifiques, ce qui peut allonger les cycles de diffusion.
La situation contrastait avec des signaux défavorables venus d’ailleurs : Lenovo a confirmé en Corée l’arrêt de son plan de mises à jour pour ses machines équipées, laissant les propriétaires de Legion Go sans nouveaux pilotes officiels. Sur ROG Ally, au moins une livraison reprend, mais sans garantie de cadence.
Un support fragmenté entre OEMs et configurations cTDP
La responsabilité de l’irrégularité reste floue entre AMD et les OEMs. Les variantes de configuration liées au cTDP 9–30 W exigent des campagnes de test par modèle avant diffusion publique, ce qui morcelle le calendrier. Pendant ce temps, certains utilisateurs basculent vers Linux pour prolonger la durée de vie logicielle via des pilotes communautaires.
ASUS montre un signe de suivi minimal, là où Lenovo concentre désormais ses ressources sur des SoC plus récents. Pour les possesseurs de ROG Ally, cette reprise peut stabiliser la compatibilité jeu par jeu à court terme. L’absence de visibilité sur la prochaine fenêtre de publication maintient toutefois un risque de stagnation.
Le contraste ASUS/Lenovo illustre un support pilote désormais piloté par les OEMs plutôt que par une filière unifiée. À moyen terme, l’avantage ira aux plateformes avec pipelines de validation courts et intégration logicielle maîtrisée, surtout sur des SoC mobiles à enveloppes TDP variables.
Adobe lance « Quick Cut » dans Firefly, une fonction d’assemblage automatique qui génère un premier cut à partir d’instructions en langage naturel. L’outil sélectionne les plans pertinents, enchaîne les séquences avec des transitions cohérentes et peut insérer des B‑rolls, le tout directement dans l’éditeur vidéo Firefly.
Un premier montage assisté, piloté par texte
Dans l’interface, un champ de prompts permet de définir l’objectif créatif, le format d’image, le tempo des transitions ou d’ajouter des médias complémentaires. Quick Cut s’applique à l’ensemble d’un projet, à une seule timeline ou à un segment précis, selon le besoin.
Adobe précise que la sortie vise un rough cut exploitable, mais pas une version finalisée. Les créateurs restent aux commandes pour l’affinage, la direction artistique et la signature visuelle. Mike Folgner, en charge des produits vidéo et IA, met en avant le gain de temps sur les tâches répétitives au profit du travail de style.
Capacités en hausse sur la suite vidéo Firefly
Quick Cut s’inscrit dans l’évolution récente de Firefly côté montage. En décembre, Adobe a ajouté un éditeur basé sur une timeline avec calques et commandes textuelles pour manipuler des objets (échelle, rotation, etc.). Firefly prend déjà en charge l’édition vidéo par prompts pour ajuster éléments de scène, colorimétrie et angles de caméra, avec une gestion plus claire des frames, de l’audio et des détails via la vue timeline.
Au‑delà de l’effet d’annonce, l’intérêt est pragmatique : accélérer le dérushage et la construction d’un squelette narratif, là où se concentrent les goulots d’étranglement en social, pub et contenus courts. Si la promesse de transitions « intelligentes » et de B‑rolls génératifs tient la route sans artefacts, Adobe consolidera une position déjà forte face aux éditeurs NLE historiques qui ajoutent l’IA par briques plutôt que par flux de travail intégré.
Quelques jours après son arrivée chez OpenAI, Peter Steinberger, connu comme le « père du homard » pour son bot iMessage, livre un entretien dense où il déroule la genèse d’OpenClaw, ses angles morts de sécurité et une manière de travailler avec les agents IA qui tranche avec les habitudes des devs seniors. Ton direct, peu de vernis, et des aveux qui piquent : « la plupart du code est ennuyeux », « on ne peut pas empêcher les abus, seulement éviter la casse ».
De la pause forcée à l’obsession OpenClaw
Après treize ans à piloter PSPDFKit, Steinberger raconte un coup de frein net, puis un électrochoc en testant Claude Code. Il emballe un projet inachevé en Markdown, demande une spec, pipeline d’auto-tests, et voit un prototype passer de zéro à « ça tourne » en une heure, malgré un code « moyen ». La bascule n’est pas la qualité, c’est le débit: tout à coup, ce qui n’était pas faisable devient atteignable à vue humaine.
Les mois suivants, il enchaîne des dizaines d’expériences publiques. Le fil conducteur n’était pas un « masterplan » mais une série de preuves d’usage: lire ses historiques, agir à sa place, manipuler des outils locaux, survivre à des réseaux pourris, traduire des images, pousser des messages pour lui. Un moment charnière: un vocal sans extension traité de bout en bout par l’agent, qui détecte l’encodage Opus, convertit via un outil local, trouve une clé d’environnement et passe en transcription en ligne. Pour Steinberger, c’est la démonstration que l’autonomie émerge dès qu’on donne un trousseau d’outils cohérent à la machine.
À l’automne, il balance un premier OpenClaw « bricolé en une heure », puis itère jusqu’au cinquième nom. Il l’utilise pour se déboguer lui-même, le lâche dans un Discord sans sandbox au départ, observe un agent qui se relance après arrêt via un service auto-restart, et va jusqu’à nommer son Mac Studio « château ». Il place un fichier canari avec valeurs et garde-fous, constate des tentatives de prompt injection, et des refus parfois cinglants du modèle. Depuis, une sandbox a été ajoutée.
Intentions avant le code, et 2 000 PR à filtrer
OpenClaw a déjà absorbé près de 2 000 PR. Steinberger ne fait pas du review ligne par ligne en première intention: il commence par l’intention. Beaucoup de contributions portent une solution locale qui ne s’insère pas au bon endroit de l’architecture. Il préfère clarifier le problème avec le modèle, cadrer s’il s’agit d’un sujet de design, de plateforme ou d’implémentation, puis seulement toucher aux branches et au merge. Même quand il réécrit, il conserve l’attribution: « les idées comptent ».
Sa posture d’auteur a évolué avec les agents: il optimise la base pour qu’un agent y performe, ce qui ne recoupe pas exactement l’ergonomie pour humains. Le code n’a pas à coller à son esthétique, l’orientation prime; si un goulot réel apparaît, on optimise. Et il assume une lecture de code minimale tant que le modèle mental colle à la sortie et que l’UX cible est satisfaite.
Sécurité, mésusages et limites d’un projet « personnel »
Sur la sécurité, le constat est froid: il ne peut pas empêcher les mésusages. Un outil web pensé pour du réseau de confiance s’est retrouvé exposé en clair, malgré les avertissements répétés dans la doc. Dès lors qu’une configuration permet l’exposition, la surface de risque grimpe et les chercheurs ont raison de le pointer. Il a intégré un spécialiste sécu et travaille à compatibiliser ces usages « non prévus » tout en essayant d’empêcher les sorties de route évidentes. Message implicite: « ne jouez pas avec le feu », mais le feu circule déjà.
Côté ergonomie, l’objectif reste paradoxal: que sa mère puisse l’installer, tout en gardant un terrain de jeu pour bidouilleurs. Par défaut, l’agent tourne au plus près du code source, le comprend et peut s’auto-modifier sur demande. Résultat inattendu: des débutants en PR participent via des « demandes d’intention » plutôt que de longues branches, l’agent servant d’exécuteur ou de médiateur technique.
Méthode de travail avec les modèles
Le passage à un environnement type Codex a densifié son activité GitHub: pas seulement grâce au modèle, mais via une intégration plus fluide dans sa routine. Il met en garde contre le « piège des agents » fait de sur-configuration stérile. Sa pratique est frugale: expliquer l’objectif, demander les questions bloquantes, garder la carte mentale globale et découper en modules indépendants pour paralléliser sans collision.
Pour l’écosystème dev, le message est clair: l’avantage compétitif bascule vers ceux qui apprennent à manier ces outils avec rapidité et discernement. Si la cadence d’OpenClaw tient, on pourrait voir se normaliser des workflows où l’intention architecturale, vérifiée par agents, prime sur la micro-police du code, avec un corollaire industriel évident: moins de friction pour prototyper des intégrations locales puissantes, mais une dette sécurité à traiter dès la conception, surtout lorsque l’agent touche aux clés, aux fichiers et aux services personnels.
Nouvelle CEO, nouvelle feuille de route : Microsoft Gaming affiche un retour assumé à l’ADN Xbox, en redonnant à la console et aux licences maison un rôle central. En toile de fond, la prochaine génération de hardware se profile autour de 2028.
Xbox recentre sa stratégie sur la console et ses productions internes
Dans un entretien à Windows Central, Asha Sharma, nouvelle CEO de Microsoft Gaming, fixe un cadre sans ambiguïté : retour à l’ADN Xbox, avec la console comme point de départ et une réduction des barrières entre appareils. Elle insiste sur un investissement accru pour permettre aux développeurs de cibler plusieurs matériels via un seul pipeline de build.
Sharma assume une phase d’audit interne : comprendre le « pourquoi » des décisions passées et piloter à la valeur vie client plutôt qu’à l’efficacité court terme. Elle rappelle un engagement vis-à-vis des fans historiques investis depuis 25 ans dans l’écosystème et ses univers.
Sur l’IA générative, le positionnement reste utilitariste. Outils oui, dérives non. « Je ne noierai pas l’écosystème sous du slop », tranche-t-elle, refusant les contenus bâclés ou dérivatifs.
Next-gen autour de 2028 : vers un hybride PC-console
Les deux dirigeants confirment que la prochaine étape se joue sur le hardware next-gen, avec un lancement évoqué autour de 2028 et une orientation hybride PC-console. Objectif affiché : lisser l’expérience entre types d’appareils et renforcer l’attractivité pour les studios, des choix d’architecture jusqu’aux outils.
Intégration précoce hardware/first-party
Matt Booty, Chief Content Officer, précise que l’organisation est conçue pour le first-party, avec une implication directe dans les décisions matérielles amont. Il cite l’optimisation de titres comme Gears of War pour de nouveaux appareils, citant l’exemple de la Xbox Ally, et réaffirme le rôle de pilier éditeur interne en synergie avec l’équipe plateforme.
Si l’orientation multiplateforme reste présente (« rencontrer les joueurs où ils sont »), le message central est la consolidation de l’offre console, soutenue par des outils unifiés et des builds mutualisés afin de limiter la fragmentation et accélérer les déploiements.
Le repositionnement met la pression sur la feuille de route hardware et sur la qualité du pipeline first-party. S’il est tenu, l’hybride PC-console de 2028 pourrait clarifier la proposition Xbox côté performance, déploiement et support développeurs, à condition d’aligner outils, SDK et calendrier studios.
Un bug de lecture VRAM pouvait fausser les stats. Valve l’a corrigé côté client, avec impact direct sur la fiabilité des prochains relevés.
Steam met à jour le client Beta et corrige la VRAM
Valve a déployé une correction dans le Steam Client Beta daté du 24 février 2026 pour un problème de reporting matériel affectant le Hardware and Software Survey. La VRAM de certaines cartes graphiques était mal remontée, biaisant la distribution publiée.
Le nombre de systèmes touchés n’est pas précisé. Les notes de version confirment toutefois que des valeurs incorrectes pouvaient être enregistrées sur certains GPU, avec un effet direct sur les parts par capacités mémoire affichées.
Sélection du GPU affiché et reporté revue
En configuration multi-adaptateurs, Steam choisit désormais l’adaptateur disposant de la plus grande quantité de VRAM pour l’affichage et le reporting. L’objectif est de limiter les cas où l’iGPU ou un adaptateur secondaire remplace à tort la carte dédiée principale.
Le relevé de janvier 2026 montrait une part importante de systèmes à 8 Go de VRAM. L’ampleur de la distorsion liée au bug reste inconnue, mais l’aveu de Valve indique des entrées mal renseignées avant ce correctif.
Impact attendu sur les prochaines publications
La mise à jour étant cantonnée au client Beta, l’effet sur les résultats de février devrait être limité. Le correctif produira un impact net une fois déployé sur le canal stable, avec un décalage probable d’un cycle de sondage pour que la correction se reflète pleinement dans les données.
Les critiques récurrentes visent souvent des déréférencements côté Radeon en présence d’iGPU et de dGPU. Le nouveau critère “plus de VRAM” devrait réduire ces erreurs sur les configurations modernes mêlant Radeon intégré et GeForce RTX série 50, même si des cas limites peuvent persister selon les drivers et l’ordre d’initialisation.
Si la correction stabilise la sélection d’adaptateur et la capacité mémoire, la photographie du parc PC côté VRAM pourrait évoluer à la marge, notamment sur les segments 6/8/12 Go où l’iGPU biaisait certains relevés. C’est un point de vigilance pour interpréter les courbes de parts dans les prochains mois.
« J'aide mon chien à faire du vibe coding » : sa chienne ne comprend pas ce qu'elle fait et pourtant ses jeux tournent, ce que l'expérience de l'ancien ingénieur de Meta dit du vibe coding
Un ancien ingénieur de recherche licencié par Meta a transformé l'accident de sa chienne sur son clavier en une démonstration technique qui dérange : avec le bon scaffolding, même un cavapoo de 4 kilos motivé par des croquettes peut produire des jeux vidéo jouables. Ce projet aussi absurde que révélateur expose...
C'est un retour inattendu après une pause de plusieurs années. Le projet LibreOffice Online renaît de ses cendres pour une version web de la suite bureautique open source.
La version PC de Death Stranding 2 : On the Beach est officiellement attendue pour le 19 mars 2026. Les précommandes sont d’ores et déjà ouvertes sur Steam et l’Epic Games Store, confirmant l’arrivée rapide du nouveau projet de Kojima Productions sur nos machines. Après un premier opus techniquement ambitieux, cette suite promet une nouvelle […]
Avec des dies GDDR7 de 24Gb annoncés jusqu’à 36 Gb/s, la mémoire graphique fixe un nouveau plafond théorique. Problème : aucun GPU commercial n’exploite encore ces débits, et l’écosystème grand public reste freiné par les coûts et l’approvisionnement.
Micron formalise la GDDR7 24 Go jusqu’à 36 Gb/s
Micron officialise des dies GDDR7 de 24Gb (3 Go) annoncés jusqu’à 36 Gb/s. Aucun GPU commercial ne tape encore cette vitesse, mais le plafond théorique est posé. Sur un bus 512-bit, on dépasse 2 TB/s de bande passante mémoire, hors limites artificielles côté contrôleur.
La densité 24Gb est déjà en circulation. NVIDIA a adopté des modules 3 Go sur la GeForce RTX 5090 Laptop GPU et la RTX PRO 6000 Blackwell. Si l’on n’a pas vu de GeForce « SUPER » sur desktop au CES, la cause la plus crédible reste un approvisionnement tendu et des prix encore élevés.
GDDR7 front and back facing right on black background
Façonner l’avenir de l’informatique immersive et intelligente. La GDDR7 de Micron ne se limite pas à un simple gain de performances : elle pose les bases technologiques de la prochaine décennie dédiée au calcul graphique et à l’IA. Avec un débit atteignant 36 Gb/s, une densité de 24 Gb et une efficacité énergétique renforcée, la GDDR7 permet aux concepteurs de GPU et de PC orientés IA de proposer des expériences de calcul plus riches, plus fluides et nettement plus intelligentes.
Côté workstation desktop, la plus grosse config GDDR7 publique reste la RTX PRO 6000, avec 96 Go via des puces 3 Go et un débit à 28 Gb/s. La carte affiche 1,8 TB/s de bande passante totale. En passant à 36 Gb/s sur la même interface, on viserait environ 2,3 TB/s, capacité inchangée.
Le bénéfice pour le grand public dépendra surtout des bus 128-bit, 192-bit et 256-bit. Des puces 24Gb autorisent des VRAM plus hautes à largeur de bus constante, ce qui peut stabiliser les coûts PCB tout en relevant le plancher de capacité pour les futures GeForce et Radeon.
Conséquences pour le marché des GPU
À court terme, l’absence de refresh RTX 50 SUPER et la tension prix/disponibilité limitent l’impact côté gaming. À moyen terme, la GDDR7 24Gb ouvre une marge nette sur la bande passante et la capacité, de quoi sécuriser des configurations 12–24 Go sur 192–256-bit et lisser les coûts tout en préparant des fréquences plus agressives lorsque l’écosystème contrôleur et l’offre fonderie s’aligneront.
Un simple déblocage de puissance ne suffit pas à libérer un prototype aussi extrême. À plus de 550 W, cette RTX 3080 Ti ES sature thermiquement, throttle violemment et impose une reconstruction complète du refroidissement, du die jusqu’à la GDDR6X arrière.
RTX 3080 Ti 20 Go : échantillon hybride sous pilotes patchés
Un moddeur détaille les avancées sur une GeForce RTX 3080 Ti Founders Edition de pré-série équipée de 20 Go de GDDR6X. La carte mêle bus 320-bit et modules mémoire arrière façon RTX 3090, et n’opère qu’avec des pilotes patchés non officiels. Il ne s’agit pas d’un SKU commercial, mais d’un échantillon d’ingénierie GA102-250 déjà démonté et benché auparavant, avec des performances proches d’une RTX 3080 sous limite de puissance conservatrice.
Le nouveau travail vise à lever les limites de puissance puis à corriger le refroidissement, source de throttling et d’instabilités une fois la consommation débridée. À stock, la limite relevée tournait autour de 390 W.
Shunt mod à 10 mΩ et pics à 555 W
Le moddeur a empilé des shunts de 10 mΩ sur les rails de détection du 12-pin et du slot PCIe, sans toucher aux sense mémoire et contrôleurs. Après modification, la carte tire environ 480 W en charge, avec des pointes observées à ~555 W en overclocking stable. La température du connecteur a été suivie au thermocouple et une partie de la charge passe par le slot PCIe.
Une fois la barrière de puissance levée, le GPU sature thermiquement et throttle. Solution retenue : métal liquide sur le die, pression de montage accrue via des rondelles de 0,5 mm, et passage de pads thermiques 12 W/mK à 20 W/mK. Résultat annoncé : 31 °C au repos et fin du throttling cœur après ajustement de la pression de contact.
Mémoire arrière à 100–102 °C, stabilisée à 94 °C
Le goulot restant concerne la GDDR6X, du fait d’un refroidisseur de RTX 3080 Ti associé à un PCB avec mémoire arrière. Les jonctions mémoire atteignaient 100–102 °C en charge soutenue avec artefacts. L’ajout de radiateurs externes sur la coque et d’un ventilateur dédié a ramené la mémoire à ~94 °C en ray tracing intensif.
À overclock identique aux essais précédents, les scores 3DMark progressent : Speedway 5492 (contre 5403), Steel Nomad 5338 (contre 5155), Port Royal 14337 (contre 13947). Gain modeste mais réel une fois la limite de puissance et la tenue thermique corrigées.
Au-delà de la curiosité technique, ce prototype illustre les contraintes d’un design hybride 320-bit avec mémoire arrière sur un refroidisseur non adapté : l’enveloppe de 480–555 W exacerbe les deltas de contact et impose une gestion fine de la pression, des interfaces thermiques et du flux d’air ciblé sur la GDDR6X.
L’arrivée d’un module GPU donné pour 600 à 1000 W bouleverse l’équilibre thermique des châssis serveurs. La conséquence est immédiate : pour exploiter pleinement ce niveau de puissance, un apport d’air externe à forte pression devient indispensable.
Akasa vapor chamber pour RTX 5090 et RTX PRO 6000
Akasa prépare un dissipateur serveur mêlant base à chambre à vapeur et empilement d’ailettes haute densité, pensé pour un flux d’air externe. La cible annoncée couvre les GPU NVIDIA GeForce RTX 5090 et NVIDIA RTX PRO 6000, avec une plage de dissipation indiquée entre 600 W et 1000 W TDP selon la configuration.
Le positionnement dépasse les besoins habituels des cartes additionnelles de station de travail. L’approche suggère un module thermique remplaçable, distinct d’un système de refroidissement complet, utilisable dans des châssis offrant un débit élevé et une forte pression statique.
Akasa n’a pas communiqué de dimensions, d’interfaces de montage ni de compatibilité au-delà des classes de cartes mentionnées. L’adaptation à des PCB spécifiques, à des designs « flow-through » multi-cartes, ou à des GPU PCIe de type serveur avec zones d’exclusion standardisées reste à confirmer.
Autres solutions et calendrier
En parallèle, la société présente des ventirads LGA-1700/1851 pour systèmes 1U low-profile, donnés pour des TDP jusqu’à 125 W. Le tout est préparé en amont d’Embedded World 2026 à Nuremberg, Allemagne, prévu du 10 au 12 mars.
Si les capacités annoncées sont confirmées en production, ce module pourrait intéresser les intégrateurs qui cherchent à unifier la gestion thermique de GPU haut de gamme via le châssis plutôt que via des refroidisseurs par carte, simplifiant la maintenance et la flexibilité des configurations.