Dossier de Han HELOIR, EMEA Gen AI Solutions Architect (MongoDB)
La quantification vectorielle : Réduire pour mieux produire
1. Pourquoi compresser les vecteurs ?
La quantification vectorielle est une méthode de compression des embeddings, qui consiste à réduire la précision des vecteurs pour diminuer leur taille en mémoire et leurs besoins en calcul. Cette approche s’inscrit dans une stratégie globale d’optimisation des systèmes d’IA générative, où chaque milliseconde et chaque octet comptent.
Sans quantification, les vecteurs sont généralement stockés en float32, un format numérique utilisant 32 bits par dimension. Cela garantit une précision élevée mais engendre des coûts de stockage exorbitants, une augmentation des latences, et des contraintes pour la scalabilité. La quantification répond à ces défis en réduisant la taille des vecteurs tout en maintenant une précision suffisante pour les tâches courantes.
2. Les trois grandes méthodes de quantification
Chaque méthode de quantification propose un équilibre différent entre compression, précision, et performance. Voici un tour d’horizon des principales approches :
a) Quantification scalaire (int8) : La solution universelle
La quantification scalaire réduit la précision de chaque élément d’un vecteur en le mappant à un ensemble pré-défini de niveaux, comme les 255 niveaux disponibles en format int8. Cette méthode divise la taille des vecteurs par 4x à 32x, tout en conservant une grande partie de leur précision.
Comment ça marche?
- Les valeurs maximales et minimales de chaque dimension sont identifiées dans l’ensemble de données.
- L’espace entre ces valeurs est divisé en niveaux équidistants (ex. : 255 pour int8).
- Chaque élément du vecteur est associé au niveau le plus proche, réduisant ainsi sa précision.
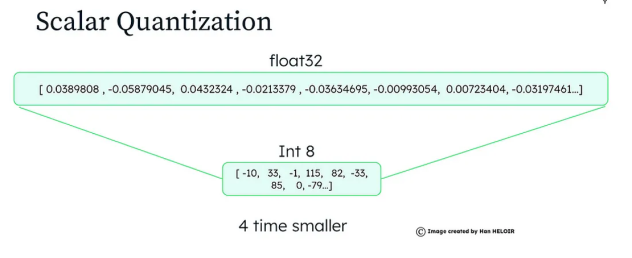
Exemple:
Un vecteur original avec des valeurs précises comme [0.456, 0.789, -0.123] pourrait être réduit à [46, 78, -12], tout en maintenant sa signification dans les recherches.
Bénéfices:
- Réduction importante des coûts de stockage.
- Compatible avec la majorité des cas d’usage, des moteurs de recherche aux systèmes de recommandations
- Conservation d’une précision élevée (jusqu’à 96 % dans certains scénarios).
b) Quantification binaire : La compacité maximale
La quantification binaire pousse la compression encore plus loin en réduisant chaque élément à une valeur binaire (0 ou 1). Cela réduit drastiquement les besoins en stockage, mais au prix d’une perte de précision plus marquée.
Comment ça marche?
- Les vecteurs sont normalisés dans un espace restreint, souvent entre -1 et 1.
- Chaque élément est évalué : s’il est positif, il devient 1 ; sinon, 0.

Exemple :
Un vecteur [0.45, -0.23, 0.78] deviendrait [1, 0, 1].
Bénéfices :
- Compression maximale, divisant les besoins de stockage par 32x à 64x.
- Temps de calcul réduit grâce à des représentations simplifiées.
Risque de perte de précision, nécessitant des techniques complémentaires comme le rescoring ou l’oversampling.
c) Quantification par produit (PQ) : La solution modulaire
La quantification par produit (Product Quantization - PQ) divise un vecteur de haute dimension en sous-vecteurs de taille plus petite, chacun étant compressé indépendamment. Cette méthode offre un compromis idéal entre compression, précision, et efficacité computationnelle.
Comment ça marche?
- Le vecteur est divisé en plusieurs segments (ou sous-vecteurs).
- Chaque sous-vecteur est associé à un centroïde préalablement calculé (via des algorithmes comme k-means).
- Au lieu de stocker les sous-vecteurs eux-mêmes, on ne conserve que les indices des centroïdes correspondants.
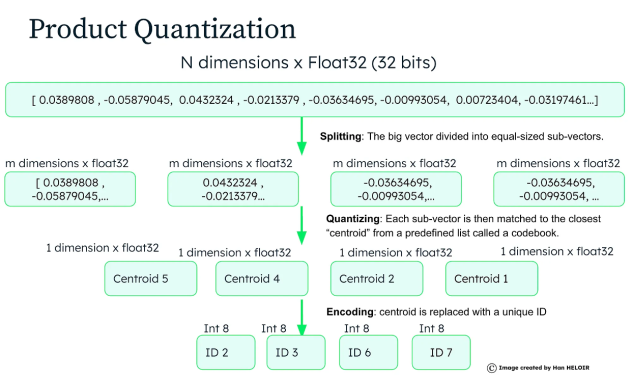
Exemple :
Un vecteur [0.45, -0.23, 0.78, -0.11] pourrait être divisé en deux sous-vecteurs [0.45, -0.23] et [0.78, -0.11], chacun étant compressé indépendamment.
Bénéfices:
- Permet une compression adaptative selon les besoins.
- Très efficace pour des systèmes traitant des milliards de vecteurs, comme FAISS (Facebook AI Similarity Search).
Performances légèrement inférieures pour les recherches en temps réel.
Cas d’usage recommandé :
- Systèmes nécessitant une forte scalabilité, comme les plateformes de commerce électronique ou les moteurs de recherche visuelle.
4. Pourquoi choisir la quantification vectorielle en production ?
a) Réduction des coûts
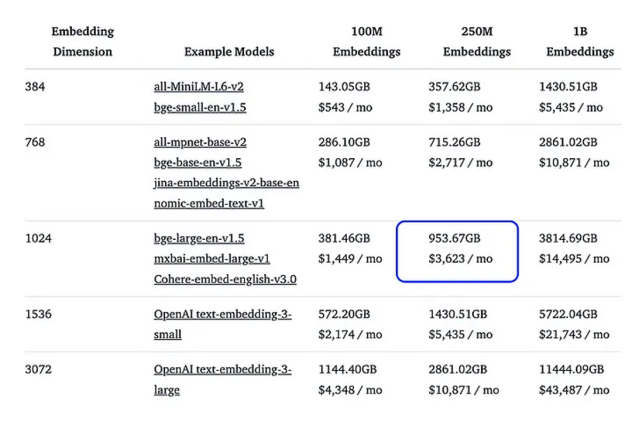
Selon une étude réalisée par HuggingFace, la quantification scalaire ou binaire peut réduire les coûts de stockage par un facteur de 20x à 30x, tout en maintenant une précision suffisante pour la majorité des cas d’usage. Par exemple : Une base contenant 250 millions de vecteurs passe de 7,5 To à 240 Go.
b) Amélioration des performances
Avec des vecteurs compressés, les recherches deviennent plus rapides car il y a moins de données à traiter. Cela se traduit par une réduction significative de la latence, essentielle pour les applications en temps réel.
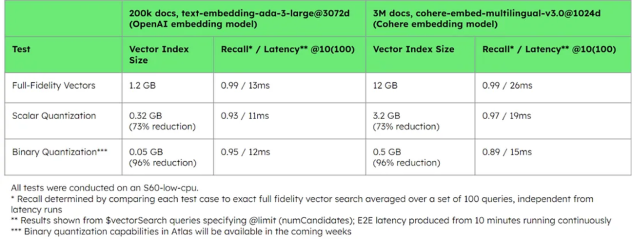
Significant storage reduction + good recall and latency performance with quantization on different embedding models(Source: MongoDB blog)
c) Scalabilité accrue
La compression permet de gérer des bases de données volumineuses sans augmenter proportionnellement les coûts en matériel ou en infrastructure cloud. Cela ouvre la voie à une scalabilité durable, même avec une augmentation rapide des utilisateurs et des requêtes.
4. Techniques avancées pour compenser la perte de précision
Oversampling : Récupère un plus grand nombre de résultats initiaux pour maximiser les chances d’inclure les éléments pertinents.
Rescoring : Affine les résultats en recalculant leur pertinence avec les vecteurs originaux (float32), garantissant des recommandations de haute qualité.
Conclusion : Construire une IA générative scalable
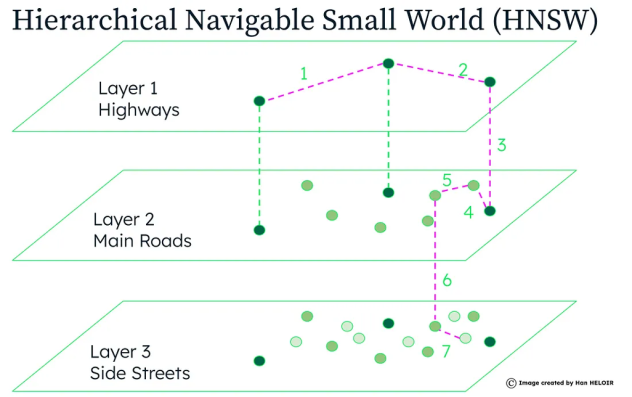
Grâce à des techniques comme la quantification vectorielle et l’indexation HNSW, les entreprises peuvent réduire leurs coûts, améliorer leurs performances, et garantir une scalabilité durable. Ces approches sont essentielles pour transformer les PoC prometteuses en solutions de production robustes et économiques.
Invitation à l’action : Explorez ces techniques dans vos projets et découvrez leur impact sur vos systèmes IA !
Références :
- HuggingFace: Binary and Scalar Embedding Quantization for Significantly Faster & Cheaper Retrieval (https://huggingface.co/blog/embedding-quantization#quantization-experiments)
- MongoDB blog: Significant storage reduction + good recall and latency performance with quantization on different embedding models (https://www.mongodb.com/blog/post/vector-quantization-scale-search-generative-ai-applications)