India has unveiled plans to build two new optical-infrared telescopes and a dedicated solar telescope in the Himalayan desert region of Ladakh. The three new facilities, expected to cost INR 35bn (about £284m), were announced by the Indian finance minister Nirmala Sitharaman on 1 February.
First up is a 3.7 m optical-infrared telescope, which is expected to come online by 2030. It will be built near the existing 2m Himalayan Chandra Telescope (HCT) at Hanle, about 4500m above sea level. Astronomers use the HCT for a wide range of investigations, including stellar evolution, galaxy spectroscopy, exoplanet atmospheres and time-domain studies of supernovae, variable stars and active galactic nuclei.
“The arid and high-altitude Ladakh desert is firmly established as among the world’s most attractive sites for multiwavelength astronomy,” Annapurni Subramaniam, director of the Indian Institute of Astrophysics (IIA) in Bangalore, told Physics World. “HCT has demonstrated both site quality and opportunities for sustained and competitive science from this difficult location.”
The 3.7-m telescope is a stepping stone towards a proposed 13.7 m National Large Optical-Infrared Telescope (NLOT), which is expected to open in 2038. “NLOT is intended to address contemporary astronomy goals, working in synergy with major domestic and international facilities,” says Maheswar Gopinathan, a scientist at the IIA, which is leading all three projects.
Gopinathan says NLOT’s large collecting area will enable research on young stellar systems, brown dwarfs and exoplanets, while also allowing astronomers to detect faint sources and to rapidly follow up extreme cosmic events and gravitational wave detections.
Along with India’s upgraded Giant Metrewave Radio Telescope, a planned gravitational-wave observatory in the country and the Square Kilometre Array in Australasia and South Africa, Gopinathan says that NLOT “will usher in a new era of multi-messenger and multi-wavelength astronomy.”
The third telescope to be supported is the 2m National Large Solar Telescope (NLST), which will be built near Pangong Tso lake 4350m above sea level. Also expected to come online by 2030, the NLST is an advance on India’s existing 50cm telescope at the Udaipur Solar Observatory, which provides a spatial resolution of about 100 km. Scientists also plan to combine NLST observations with data from Aditya-L1, India’s space-based solar observatory, which launched in 2023.
“We have two key goals [with NLST],” says Dibyendu Nandi, an astrophysicist at the Indian Institute of Science Education and Research in Kolkata, “to probe small-scale perturbations that cascade into large flares or coronal mass ejections and improve our understanding of space weather drivers and how energy in localised plasma flows is channelled to sustain the ubiquitous magnetic fields.”
While bolstering India’s domestic astronomical capabilities, scientists say the Ladakh telescopes – located between observatories in Europe, the Americas, East Asia and Australia – would significantly improve global coverage of transient and variable phenomena.
A faint flash of infrared light in the Andromeda galaxy was emitted at the birth of a stellar-mass black hole – according to a team of astronomers in the US. Kishalay De at Columbia University and the Flatiron Institute, and colleagues, noticed that the flash was followed by the rapid dimming of a once-bright star. They say that the star collapsed, with almost all of its material falling into a newly forming black hole. Their analysis suggests that there may be many more such black holes in the universe than previously expected.
When a massive star runs out of fuel for nuclear fusion it can no longer avoid gravitational collapse. As it implodes, such a star is believed to emit an intense burst of neutrinos, whose energy can be absorbed by the star’s outer layers.
In some cases, this energy is enough to tear material away from the core, triggering spectacular explosions known as core-collapse supernovae. Sometimes, however, this energy transfer is insufficient to halt the collapse, which continues until a stellar-mass black hole is created. These stellar deaths are far less dramatic than supernovae, and are therefore very difficult to observe.
Observational evidence for these stellar-mass black holes include their gravitational influence on the motions of stars; and the gravitational waves emitted when they merge together. So far, however, their initial formation has proven far more difficult to observe.
Mysterious births
“While there is consensus that these objects must be formed as the end products of the lives of likely very massive stars, there has remained little convincing observational evidence of watching stars turn into black holes,” De explains. “As a result, we don’t even have constraints on questions as fundamental as which stars can turn into black holes.”
The main problem is the low key nature of the stellar implosions. While core-collapse supernovae shine brightly in the sky, “finding an individual star disappearing in a galaxy is remarkably difficult,” De says. “A typical galaxy has a 100 billion stars in it, and being able to spot one that disappears makes it very challenging.”
Fortunately, it is believed that these stars do not vanish without a trace. “Whenever a black hole does form from the near complete inward collapse of a massive star, its very outer envelope must be still ejected because it is too loosely bound to the star,” De explains. As it expands and cools, models predict that this ejected material should emit a flash of infrared radiation – vastly dimmer than a supernova, but still bright enough for infrared surveys to detect.
To search for these flashes, De’s team examined data from NASA’s NEOWISE infrared survey and several other telescopes. They identified a near-infrared flash that was observed in 2014 and closely matched their predictions for a collapsing star. That flash was emitted by a supergiant star in the Andromeda galaxy.
Nowhere to be seen
Between 2017 and 2022, the star dimmed rapidly before disappearing completely across all regions of the electromagnetic spectrum. “This star used to be one of the most luminous stars in the Andromeda Galaxy, and now it was nowhere to be seen,” says De.
“Astronomers can spot supernovae billions of light years away – but even at this remarkable proximity, we didn’t see any evidence of an explosive supernova,” De says. “This suggests that the star underwent a near pure implosion, forming a black hole.”
The team also examined a previously-observed dimming in a galaxy 10 times more distant. While several competing theories had emerged to explain that disappearance, the pattern of dimming bore a striking resemblance to their newly-validated model, strongly suggesting that this event too signalled the birth of a stellar-mass black hole.
Because these events occurred so recently in ordinary galaxies like Andromeda, De’s team believe that similar implosions must be happening routinely across the universe – and they hope that their work will trigger a new wave of discoveries.
“The estimated mass of the star we observed is about 13 times the mass of the Sun, which is lower than what astronomers have assumed for the mass of stars that turn into black holes,” De says. “This fundamentally changes out understanding of the landscape of black hole formation – there could be many more black holes out there than we estimate.”
The International Year of Quantum Science and Technology (IYQ) has officially closed following a two-day event in Accra, Ghana. The year has seen hundreds of events worldwide celebrating the science and applications of quantum physics.
Officially launched in February at the headquarters of the UN Educational, Scientific and Cultural Organization (UNESCO) in Paris, IYQ has involved hundreds of organizations – including the Institute of Physics, which publishes Physics World.
The year 2025 was chosen for an international year dedicated to quantum physics as it marks the centenary of the initial development of quantum mechanics by Werner Heisenberg. A range of international and national events have been held touching on quantum in everything from communications and computing to medicine and the arts.
One of the highlights of the year was a workshop on 9–14 June in Helgoland – the island off the coast of Germany where Heisenberg made his breakthrough exactly 100 years ago. It was attended by more than 300 top quantum physicists, including four Nobel prize-winners, who gathered for talks, poster sessions and debates.
The closing event in Ghana, held on 10–11 February, was attended by government officials, UNESCO directors, physicists and representatives from international scientific societies, including the IOP. They discussed UNESCO’s official 2025 IYQ report as well as heard a reading of the IYQ 2025 poetry contest winning entry and attended an exhibition with displays from IYQ sponsors.
Organizers behind the IYQ hope its impact will be felt for many years to come. “The entire 2025 year was filled with impactful events happening all over the world. It has been a wonderful experience working alongside such dedicated and distinguished colleagues,” notes Duke University physicist Emily Edwards, who is a member of the IYQ steering committee. “We are thrilled to see the enthusiasm continue through to 2026 with the closing ceremony and are proud that a strong foundation has been laid for the years ahead.”
The UN has declared “international years” since 1959, to draw attention to topics deemed to be of worldwide importance. In recent years, there have been a number of successful science-based themes, including physics (2005), astronomy (2009), chemistry (2011), crystallography (2014) and light and light-based technologies (2015).
Read our two free-to-read quantum briefings, published in May and October, which feature articles on the history, mystery and industry of quantum mechanics.
Rewatch our Physics World Live: Quantum held in June that included a discussion of how technological developments have created a whole new ecosystem of “quantum 2.0” businesses
Science fiction became science fact in 2022 when NASA’s DART mission took the first steps towards creating a planetary defence system that could someday protect Earth from a catastrophic asteroid collision. However, much more work on asteroid deflection is needed from the latest generation of researchers – including Rahil Makadia, who has just completed a PhD in aerospace engineering at University of Illinois at Urbana-Champaign.
In this episode of the Physics World Weekly podcast, Makadia talks about his work on how we could deflect asteroids away from Earth. We also chat about the potential threats posed by near-Earth asteroids – from shattered windows to global destruction.
Makadia’s stresses the importance of getting a deflection right the first time, because his calculations reveal that a poorly deflected asteroid could return to Earth someday. In November, he published a paper that explored how a bad deflection could send an asteroid into a “keyhole” that guarantees its return.
But it is not all gloom and doom, Makadia points out that our current understanding of near-Earth asteroids suggests that no major collision will occur for at least 100 years. So even if there is a threat on the horizon, we have lots of time to develop deflection strategies and technologies.
Flowing fluids that act like the interlocking teeth of mechanical gears offer a possible route to novel machines that suffer less wear-and-tear than traditional devices. This is the finding of researchers at New York University (NYU) in the US, who have been studying how fluids transmit motion and force between two spinning solid objects. Their work sheds new light on how one such object, or rotor, causes another object to rotate in the liquid that surrounds it – sometimes with counterintuitive results.
“The surprising part in our work is that the direction of motion may not be what you expect,” says NYU mathematician Leif Ristroph, who led the study together with mathematical physicist Jun Zhang. “Depending on the exact conditions, one rotor can cause a nearby rotor to spin in the opposite direction, like a pair of gears pressed together. For other cases, the rotors spin in the same direction, as if they are two pulleys connected by a belt that loops around them.”
Making gear teeth using fluids
Gears have been around for thousands of years, with the first records dating back to 3000 BC. While they have advanced over time, their teeth are still made from rigid materials and are prone to wearing out and breaking.
Ristroph says that he and Zhang began their project with a simple question: might it possible to avoid this problem by making gears that don’t have teeth, and in fact don’t even touch, but are instead linked together by a fluid? The idea, he points out, is not unprecedented. Flowing air and water are commonly used to rotate structures such as turbines, so developing fluid gears to facilitate that rotation is in some ways a logical next step.
To test their idea, the researchers carried out a series of measurements aimed at determining how parameters like the spin rate and the distance between spinning objects affect the motion produced. In these measurements, they immersed the rotors – solid cylinders – in an aqueous glycerol solution with a controllable viscosity and density. They began by rotating one cylinder while allowing the other one to spin in response. Then they placed the cylinders at varying distances from each other and rotated the active cylinder at different speeds.
“The active cylinder should generate fluid flows and could therefore in principle cause rotation of the passive one,” says Ristroph, “and this is exactly what we observed.”
When the cylinders were very close to each other, the NYU team found that the fluid flows functioned like gear teeth – in effect, they “gripped” the passive rotor and caused it to spin in the opposite direction as the active one. However, when the cylinders were spaced farther apart and the active cylinder spun faster, the flows looped around the outside of the passive cylinder like a belt around a pulley, producing rotation in the same direction as the active cylinder.
A model involving gear-like- and belt-like modes
Ristroph says the team’s main difficulty was figuring out how to perform such measurements with the necessary precision. “Once we got into the project, an early challenge was to make sure we could make very precise measurements of the rotations, which required a special way to hold the rotors using air bearings,” he explains. Team member Jesse Smith, a PhD student and first author of a paper in Physical Review Letters about the research, was “brilliant in figuring out every step in this process”, Ristroph adds.
Another challenge the researchers faced was figuring out how to interpret their findings. This led them to develop a model involving “gear-like” and “belt-like” modes of induced rotations. Using this model, they showed that, at least in principle, a fluid gear could replace regular gears and pulley-and-belt systems in any system – though Ristroph suggests that transmitting rotations in a machine or keep timing via a mechanical device might be especially well-suited.
In general, Ristroph says that fluid gears offer many advantages over mechanical ones. Notably, they cannot become jammed or wear out due to grinding. But that isn’t all: “There has been a lot of recent interest in designing new types of so-called active materials that are composed of many particles, and one class of these involves spinning particles in a fluid,” he explains. “Our results could help to understand how these materials behave based on the interactions between the particles and the flows they generate.”
The NYU researchers say their next step will be to study more complex fluids. “For example, a slurry of corn starch is an everyday example of a shear-thickening fluid and it would be interesting to see if this helps the rotors better ‘grip’ one another and therefore transmit the motions/forces more effectively,” Ristroph says. “We are also numerically simulating the processes, which should allow us to investigate things like non-circular shapes of the rotors or more than just two rotors,” he tells Physics World.
A new class of biomolecules called magneto-sensitive fluorescent proteins, or MFPs, could improve imaging of biological processes inside living cells and potentially underpin innovative therapies.
The fluorescent proteins commonly used in biological studies respond solely to light being shone at them. But because that light gets scattered by tissues there are inaccuracies in determining exactly where the resulting fluorescence originates. By contrast, the MFPs created by a team led by Harrison Steel, head of the Engineered Biotechnology Research Group at the University of Oxford in the UK, fluoresce partly in response to highly predictable magnetic fields and radio waves that pass through biological tissues without deflection.
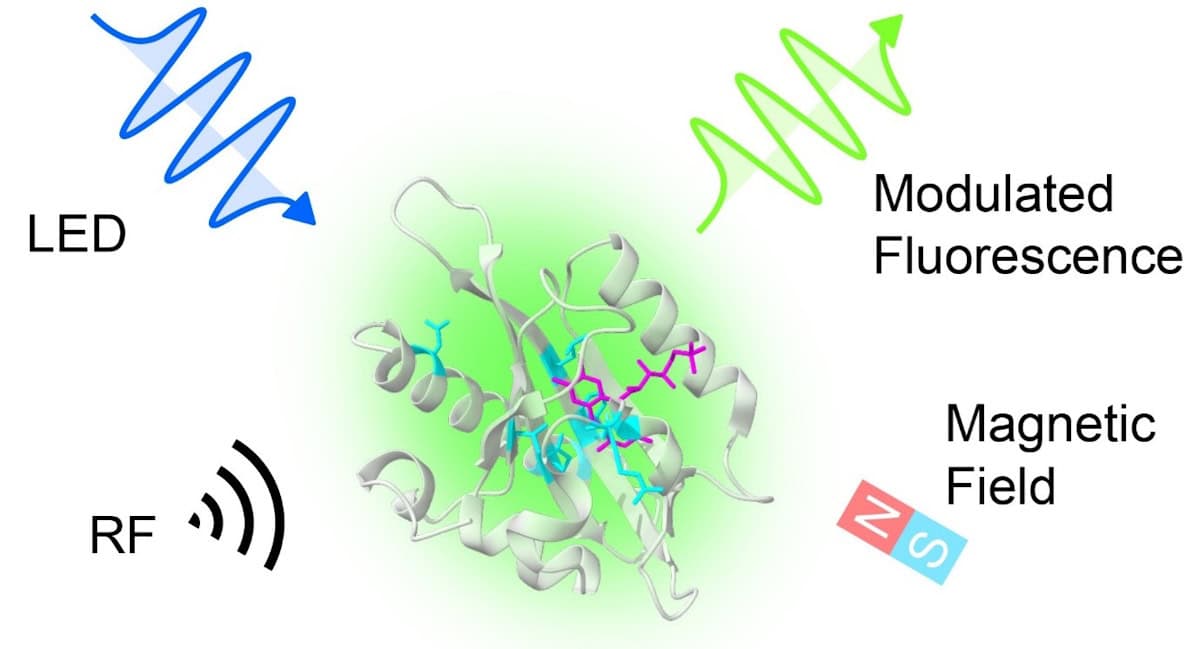
Sensor schematic An MFP excited by blue light emits green fluorescence, the intensity of which can be modulated by applying appropriate magnetic or radiofrequency fields. (Courtesy: Gabriel Abrahams)
To detect where MFPs are located within living cells, the researchers apply both a static magnetic field with a precisely known gradient and a radiofrequency (RF) signal, which modulate the fluorescence triggered via excitation by a light-emitting diode (LED).
The emitted fluorescence is brightest whenever the RF is in resonance with a transition energy of the entangled electron system present within the MFP. Since the resonance frequency depends on the surrounding magnetic field strength, the brightness reveals the protein’s location.
As detailed in their recent Nature paper, the researchers engineered the MFPs by “directed evolution”: starting with a DNA sequence, making two to three thousand variants of it, and selecting the variants with the best fluorescence response to magnetic fields before repeating the entire process multiple times. The resulting proteins were tested via ODMR (optically detected magnetic resonance) and MFE (magnetic-field effect) experiments, revealing that they could be detected in single living cells and sense their local microenvironment.
Importantly, these MFPs can be made in research labs using a straightforward biological technique. “This is a totally different way of coming up with new quantum materials compared to other engineering efforts for quantum sensors like nitrogen vacancies [in diamonds] which need to be manufactured in highly specialized facilities,” explains first author Gabriel Abrahams, a doctoral student in Steel’s research group. Abrahams helped develop quantum diamond microscopes during his master’s in physics at the Quantum Nano Sensing Lab in Melbourne, Australia before moving onto the Oxford Interdisciplinary Bioscience Doctoral Training Programme.
The MFPs were inspired by the work of study co-authors Maria Ingaramo and Andy York, both then working for Calico Life Sciences. They had observed a small change in fluorescence when a magnet interacted with a quantum-enabled protein, explains Abrahams. “That was really cool! I hadn’t seen anything like that, and there were clearly potential applications if it could be made better,” he says.
Steel tells Physics World that “a lot of the past work in quantum biology was with fragile proteins, often at cryogenic temperatures. Surprisingly you could easily measure these MFPs in single living cells every few minutes as they can work for a long time at room temperature”. Furthermore, using MFPs only requires adding a magnet to existing fluorescence microscopy equipment, allowing new data to be cost-effectively obtained.
“For instance, you might use three or four fluorescent proteins to tag natural processes in a mammalian cell in a petri dish to see when they are being used and where they go. We could instead tag with 10 or 15 MFPs, allowing you to measure extra targets by just applying a magnetic field,” Steel explains.
Quantum engineer Peter Maurer from the University of Chicago in the US, who was not involved in the study, is enthusiastic about these new MFPs. “By combining magnetic fields and fluorescence, this work establishes an exciting new imaging modality with broad potential for future evolution. Notably, similar approaches could be directly applicable to qubits [quantum bits], such as the fluorescent protein qubits our team published in Nature last year,” he says.
Next, Steel intends to improve their instrumentation for using MFPs – much of which was adopted from researchers investigating how birds navigate via the earth’s magnetic field. Future MFP applications could include microbiome studies sensing where bacteria travel in our bodies, and the development of highly controllable actuators for drug delivery. “If you would like to turn on the protein’s ability to bind to a cancer cell, for example, you could simply put a magnet on the outside of a person in the right location,” he concludes.
Royal approval (Clockwise from top left) The Duke of Edinburgh with IOP group chief executive Tom Grinyer; talking to Selina Ambrose from Promethean Particles; the exhibition he toured; and speaking after the panel debate. (Courtesy: Carmen Valino)
The Duke of Edinburgh visited the headquarters of the Institute of Physics (IOP) in central London on 5 February to learn about the role that physics plays in supporting the green economy.
The event was attended by about 100 business leaders, policy chiefs, senior physicists, and IOP and IOP Publishing staff. It highlighted how physics research is helping to deliver clean energy solutions and support economic growth.
A total of 12 companies took part in an exhibition that was visited by the duke. They included two carbon-capture firms – Nellie Technologies and Promethean Particles – as well as the fusion firm Tokamak Energy and Sunamp, which makes non-flammable “thermal batteries”.
The event included a panel debate chaired by Tara Shears, the IOP’s vice-president for science and innovation.
It featured ex-BP boss John Browne, who now works in green energy, along with Sizewell C energy-strategy director David Cole, Nellie Technologies founder Stephen Millburn, solar-cell physicist Jenny Nelson from Imperial College, and Emily Nurse from the UK’s Climate Change Committee.
After the debate, the duke said the event had showcased “some of the brilliant ideas that are trying to solve some really challenging issues through creativity and imagination”. He expressed particular delight that people are central to that mission.
“Our ability to evolve the right skills for the future has been well demonstrated here,” he said. “It comes down to creating the right climate to allow these ideas to flourish and come to market. We simply cannot drop this issue.”
Tom Grinyer, group chief executive of the IOP, reminded delegates that physics is fundamental to the UK economy. “We’re seeing how research is translating into real-world solutions that matter today, from clean power and climate intelligence, to advanced materials and future technologies,” he said.
But he warned that long-term investment in young people will be vital to create the physicists and business leaders who can tackle those challenges.
Re-entry of space debris. Courtesy: S Economon and B Fernando
When chunks of space debris make their fiery descent through the Earth’s atmosphere, they leave a trail of shock waves in their wake. Geophysicists have now found a way to exploit this phenomenon, using open-source seismic data from a network of earthquake sensors to monitor the waves produced by China’s Shenzhou-15 module as it fell to Earth in April 2024. The method is valuable, they say, because it makes it possible to follow debris – which can be hazardous to humans and animals – in near-real time as they travel towards the surface.
“We’re at the situation today where more and more spacecraft are re-entering the Earth’s atmosphere on a daily basis,” says team member Benjamin Fernando, a postdoctoral researcher at Johns Hopkins University in the US. “The problem is that we don’t necessarily know what happens to the fragments this space debris produces – whether they all break up in the atmosphere or if some of them reach the ground.”
Piggybacking on a network of earthquake sensors
As the Shenzhou-15 module re-entered the atmosphere, it began to disintegrate, producing debris that travelled at supersonic speeds (between Mach 25‒30) over the US cities of Santa Barbara, California and Las Vegas, Nevada. The resulting sonic booms produced vibrations strong enough to be picked up by a network of 125 seismic stations spread over Nevada and Southern California.
Fernando and his colleague Constantinos Charalambous at Imperial College London in the UK used freely available data from these stations to measure the arrival times of the largest sonic boom signals. Based on these data, they produced a contour map of the path the debris took and the direction in which it propagated. They also determined the altitude of the module as it travelled by using ratios of the speed of sound to the apparent speed of the incident wavefront its supersonic flight generated as it passed over the seismic stations. Finally, they used a best-fit seismic inversion model to estimate where remnants of the module may have landed and the speed at which they travelled over the ground.
The analyses revealed that the module travelled roughly 20-30 kilometres south of the trajectory that US Space Command had predicted based on measurements of the module’s orbit alone. The seismic data also showed that the module gradually disintegrated into smaller pieces rather than undergoing a single explosive disassembly.
Advantages of accurate tracking
To obtain an estimate of the object’s trajectory within seconds or minutes, the researchers had to simplify their calculations by ignoring the effects of wind and temperature variations in the lower troposphere (the lowest layer of the Earth’s atmosphere). This simplification also did away with the need to simulate the path of wave signals through the atmosphere, which was essential for previous techniques that relied on radar data to follow objects decaying in low Earth orbit. These older techniques, Fernando adds, produced predictions of the objects’ landing sites that could, in the worst cases, be out by thousands of kilometres.
The availability of accurate, near-real time debris tracking could be particularly helpful in cases where the debris is potentially harmful. As an example, Fernando cites an incident in 1996, when debris from the Russian Mars 96 spacecraft fell out of orbit. “People thought it burned up and [that] its radioactive power source landed intact in the ocean,” he says. “They tried to track it at the time, but its location was never confirmed. More recently, a group of scientists found artificial plutonium in a glacier in Chile that they believe is evidence the power source burst open during the descent and contaminated the area.”
Though Fernando emphasizes that it’s rare for debris to contain radioactive material, he argues “we’d benefit from having additional tracking tools” when it does.
Towards an automated algorithm for trajectory reconstruction
Fernando had previously used seismometers to track natural meteoroids, comets and asteroids on both Earth and Mars. In the latter case, he used data from InSight, a NASA Mars mission equipped with a seismometer.
“The meteoroids hitting the Red Planet were a really good seismic source for us,” he explains. “We detected the sonic booms from them breaking up and, occasionally, would actually detect the impact of them hitting the ground. We realized that we could actually apply those same techniques to studying space debris on Earth.
“This is an excellent example of a technique that we really perfected the expertise for a planetary science kind of pure science application. And then we were able to apply it to a really relevant, challenging problem here on Earth,” he tells Physics World.
The scientists say that in the longer term, they hope to develop an algorithm that automatically reconstructs the trajectory of an object. “At the moment, we’re having to find the sonic boons and analyse the data ‘by hand’,” Fernando says. “That’s obviously very slow, even though we’re getting better.”
A better solution, Fernando continues, would be to develop a machine learning tool that can find sonic booms in the data when a re-entry is expected, and then use those data to reconstruct the trajectory of an object. They are currently applying for funding to explore this option in a follow-up study.
Beyond that, there’s also the question of what to do with the data once they have it. “Who would we send the data to?” Fernando asks rhetorically. “Who needs to know about these events? If there’s a plane crash, hurricane, or similar, there are already good international frameworks in place for dealing with these events. It’s not clear to me, however, that such a framework for dealing with space debris has caught up with reality – either in terms of regulations or the response when such an event does happen.”
A proposed industrial-scale green hydrogen and ammonia project in Chile that astronomers warned could cause “irreparable damage” to the clearest skies in the world has been cancelled. The decision by AES Andes, a subsidiary of the US power company AES Corporation, to shelve plans for the INNA complex has been welcomed by the European Southern Observatory (ESO).
AES Andes submitted an Environmental Impact Assessment for the green hydrogen project in December 2024. Expected to cover more than 3000 hectares, it would have been located just a few kilometres from ESO’s Paranal Observatory in Chile’s Atacama Desert, which is one of the world’s most important astronomical research sites due to its stable atmosphere and lack of light pollution.
That same month, ESO conducted its own impact assessment, concluding that INNA would increase light pollution above Paranal’s Very Large Telescope by at least 35% and by more than 50% above the southern site of the Cherenkov Telescope Array Observatory (CTAO).
Once built, the CTAO will be the world’s most powerful ground-based observatory for very high-energy gamma-ray astronomy.
ESO director general Xavier Barcons had warned that the hydrogen project would have posed a major threat to “the performance of the most advanced astronomical facilities anywhere in the world”.
On 23 January, however, AES Andes announced that it will discontinue plans to develop the INNA complex. The firm stated that after a review of its project portfolio it had chosen to instead focus on renewable energy and energy storage. On 6 February, AES Andes sent a letter to Chile’s Environmental Assessment Service requesting that INNA is not evaluated, which formally confirmed the end of the project.
Barcons says that ESO is “relieved” about the decision, adding that the case highlights the urgent need to establish clear protection measures in the areas around astronomical observatories.
Barcons notes that green-energy projects as well as other industrial projects can be “fully compatible” with astronomical observatories along as the facilities are located at sufficient distances away.
Romano Corradi, director of the Gran Telescopio Canarias, which is located at the Roque de los Muchachos Observatory, La Palma, Spain, told Physics World that he was “delighted” with the decision.
Corradi adds that while it is unclear if preserving the night-sky darkness of the region was a relevant factor for the decision to cancel the project, he hopes that global pressure to defend the dark skies played a role.
High-energy heavy-nuclei collisions, conducted at particle colliders such as CERN’s Large Hadron Collider (LHC) and BNL’s Relativistic Heavy Ion Collider (RHIC) are able to produce a state of matter called a quark-gluon plasma (QGP).
A QGP is believed to have existed just after the Big Bang. The building blocks of protons and neutrons – quarks and gluons – were not confined inside particles as usual but instead formed a hot, dense, strongly interacting soup.
Studying this state of matter helps us understand the strong nuclear force, the early universe, and how matter evolved into the forms we see today.
In order to understand QGP created in a particle collider you need to know the initial conditions. In this case that is the shape and structure of the heavy nuclei that collided.
A major complicating factor here is that most atomic nuclei are deformed. They are not spherical but rather squashed and ellipsoidal or even pear-shaped.
Collisions of deformed nuclei with different orientations brings in a large amount of randomness and therefore hinders our ability to describe the initial conditions of the QGP.
A new method called imaging-by-smashing was developed by the STAR experiment at RHIC, where atomic nuclei are smashed together at extremely high speeds. By studying the patterns in the debris from these collisions, researchers can infer the original shape of the nuclei.
In this latest study, they compared collisions between two types of nuclei: uranium-238, which has a strongly deformed shape, and gold-197, which is nearly spherical.
The differences between uranium and gold helped isolate the effects of uranium’s deformation. Their results matched predictions from advanced hydrodynamic simulations and earlier low-energy experiments.
Most interestingly, they found hints that uranium might possess a pear-like (octupole) shape, in addition to its dominant football-like (quadrupole) shape. This feature had not previously been observed in high-energy collisions
This method is still new, but in the future, it could give us key insights nuclear structure throughout the periodic table. These measurements probe nuclei at energy scales orders of magnitudes higher than traditional methods, potentially revealing how nuclear structure evolves across very different energy regimes.
In quantum mechanics, a quantum state is a complete description of a system’s physical properties.
If the system changes slowly and returns to its original physical configuration, then its quantum state also returns to its original form except for a phase factor.
In a pioneering work in 1984, physicist Michael Berry discovered that this factor can be separated into two parts: the dynamic and the geometric phase.
The usual dynamic phase depends on energy and time and was already well understood. The new part, the geometric phase (or Berry phase after its discoverer) arises purely from the geometry of the path that the state takes through parameter space.
The Berry phase has profound implications across physics, appearing in phenomena like the quantum Hall effect, molecular dynamics, and polarised light. It reveals deep connections between geometry, topology, and physical observables.
In a recent paper, this concept was extended from wave evolution to certain wave scattering events, where waves bounce off or pass through materials and their properties shift.
In order to do this, the authors used a mathematical tool called a scattering matrix. The matrix encodes all the possible outcomes of a scattering process – reflection, transmission, or deflection -based on the system’s properties.
They showed that these wave shifts can also be split into dynamic and geometric parts. Importantly this splitting can be done in such a way that doesn’t depend on arbitrary choices (i.e., it’s gauge-invariant).
The team demonstrated their idea with known examples like light passing through a changing waveplate, beams reflecting off surfaces, and time delays in 1D systems.
Their approach is not only able to describe known phenomena, but also reveals new physical features, provides new insights, and uncovers previously unnoticed connections.
Going forward, identifying the geometric and dynamic origins of various scattering-induced shifts offers new ways to control wave-scattering phenomena.
This could have applications in photonics, imaging, quantum computing, and micromanipulation.
Radiation therapy is usually delivered by prescribing the same radiation dose for each particular type of tumour. But this “one-size-fits-all” approach does not account for a tumour’s intrinsic radiosensitivity and heterogeneity and can lead to recurrence and treatment failure. Researchers in Sweden and Germany are now investigating whether biologically individualized radiotherapy plans, created using PET images of a patient’s tumour biology, can improve treatment outcomes.
The research team – headed up by Marta Lazzeroni from Stockholm University – studied 28 patients with advanced head-and-neck squamous cell carcinoma (HNSCC). All patients underwent two pre-treatment PET/CT scans, using 18F-fluoromisonidazole (FMISO) and 18F-FDG as tracers to respectively quantify radioresistance and tumour cellularity (the percentage of clonogenic cells) – both critical factors that influence treatment response.
“FMISO provides information on hypoxia-related radioresistance, but tumour control also strongly depends on the number of clonogenic cells, which is not captured by hypoxia imaging alone,” Lazzeroni explains. “To our knowledge, this is the first study to combine FMISO and FDG PET within a unified radiobiological framework to guide biologically individualized dose escalation.”
For each patient, the researchers used FMISO uptake to derive voxel-level maps of oxygen partial pressure (pO2) in the tumour and define a hypoxic target volume (HTV). The FDG scans were used to estimate spatial variations in clonogenic tumour cell density, which directly influence the dose required to realise a given tumour control probability (TCP).
Based on individual tumour profiles, the team used automated planning to create volumetric-modulated arc therapy plans comprising 35 fractions with an integrated boost. The plans delivered escalated dose to radioresistant subvolumes (the HTV), while maintaining clinically acceptable sparing of organs-at-risk. The PET datasets were used to calculate the prescribed dose required to achieve a TCP of 95%.
Meeting clinical feasibility
The automated planning pipeline achieved high-quality treatment plans for all patients without manual intervention. The average EQD2 (the dose delivered in 2 Gy fractions that’s biologically equivalent to the total dose) to the HTV was boosted to 81±3.2 Gy, and all 28 plans met the clinical constraints for protecting the brainstem, spinal cord and mandible. Parotid glands were spared in 75% of cases, with the remainder being glands that overlapped the target.
Lazzeroni and colleagues suggest that these results confirm the overall clinical feasibility of their personalized dose-escalation strategy and demonstrate how biology-guided prescriptions could be integrated into existing treatment planning workflows.
The researchers also performed a radiobiologic evaluation of the treatment plans to see whether the optimized dose distribution achieved the desired target control. For this, they calculated the TCP based on the planned dose distribution, the PET-derived radioresistance data and clonogenic cell density maps. For all patients, the plans achieved model-predicted TCP values exceeding 90%, a notable improvement on tumour control rates reported in the clinical literature for HNSCC, which are typically around 60%.
The proposed strategy is based on pre-treatment PET images, but biological changes during treatment – including temporal and spatial variations in tumour hypoxia – could impact its effectiveness. In future, the researchers suggest that longitudinal imaging, such as PET/CT scans at weeks 3 and 5, could be used to monitor evolving tumour biology and inform adaptive replanning. This is particularly relevant in HNSCC, where tumour shrinkage and reoxygenation are common, and where updated imaging is required to determine whether dose escalation or de-escalation is appropriate to maintain tumour control and optimize normal tissue sparing.
The researchers point out that as the biology-guided dose prescriptions were planned but not delivered, prospective trials will be required to assess whether the observed dosimetric and biologic gains translate to improved patient outcomes.
“This study was designed as a feasibility and modelling investigation, and the next step is prospective clinical validation,” Lazzeroni tells Physics World. “Based on the promising results of this approach, prospective clinical trials are currently in the planning phase within the group led by Anca-L Grosu in Germany. These trials will focus on integrating longitudinal PET imaging during treatment to enable biologically adaptive radiotherapy.”
Entanglement is a key resource for quantum computation and quantum technologies, but it can also tell us much about a computational problem. That is the conclusion of a recent paper by Achim Kempf and Einar Gabbassov – who are applied mathematicians at Canada’s University of Waterloo and are affiliated with Waterloo’s Institute for Quantum Computing and the Perimeter Institute for Theoretical Physics. Writing in Quantum Science and Technology, Gabbassov and Kempf show how entanglement plays a fundamental role in determining both the efficiency and the hardness of quantum computation problems.
They considered the role of entanglement in adiabatic quantum computing. This considers a landscape of hills and valleys (the problem) where the shape of the landscape depends on the problem to be solved. A point on the landscape represents a candidate solution to the problem. This could be a configuration of possible states of three qubits, for example, or “a possible schedule for truck routes, or a particular shape for a pharmaceutical molecule” says Kempf. The actual solution to the problem is then the lowest (deepest) point in the landscape, which corresponds to the lowest energy point (the minimum point or minima).
This minima is easy to find if the landscape is smooth and has only one valley. The problem is harder if there are multiple valleys (a rugged landscape) since you might get stuck in a valley you believe to be the deepest, but which is not, and then you would have to climb out of it.
In a classical computation, every possible valley must be checked one-by-one to find the deepest one. However, Kempf explains that “in adiabatic quantum computing, the computer keeps track of all the valleys at once, by connecting them internally using entanglement”. Classically, many possibilities just means many independent guesses of the deepest valley. With quantum effects, when one part of the landscape shifts, it affects the whole landscape all at once. He explains that instead of checking each valley one-by-one, we can check them all simultaneously, significantly increasing the speed at which the lowest point in the landscape is found.
Shapeshifting landscape
When given a difficult problem with many valleys, there is a risk of getting stuck in a valley that is shallow and not being able to climb out and find the lowest energy state. Adiabatic quantum computing gets around this issue through a clever shapeshifting of the landscape.
The process starts with an easy landscape, comprising only one valley. Since the solution is simple, the the deepest valley corresponding to the lowest energy state is occupied quickly. Gradually the landscape is changed to contain more and more valleys, more closely approximating the more complicated landscape whose lowest point is the solution.
The lowest point changes with each change in the landscape, but the trick is that if the changes in the landscape are small enough, the deepest part of the landscape and therefore the lowest energy state will always be occupied. This is the basic principle of adiabatic quantum computing often used in resource allocation, routing and logistics, and machine learning where there can be huge numbers of possible variable configurations.
Difficulty and computation time
In their work, Gabbassov and Kempf explore how the amount of entanglement required to find the deepest valley links to the difficulty and time needed to complete the problem.
A difficult problem would be a rugged landscape consisting of multiple valleys of similar depth located far apart from one another. To occupy the lowest energy state, we need to occupy all these valleys simultaneously. The entanglement needed to do this is greater since the interconnectedness between the valleys is harder to maintain when they are further apart (they have a large Hamming distance). The problem is also harder to solve since it is more difficult to discern which of these valleys is the deepest when they have a similar depth – being close in energy. This added difficulty is reflected in a need for a greater amount of entanglement to keep track of the valleys but also in a greater amount of time needed to distinguish the depths of the valleys to find the deepest one.
Gabbassov and Kempf show that a large amount of entanglement is needed at these difficult, bottleneck points of the computation. This makes it even more difficult to keep track of the valleys and more time is required to avoid falling into the wrong one. This is also where classical computation would normally slow down. Quantum effects are therefore most valuable and are most crucial at these points, proving essential for identifying when and where adiabatic quantum computation can provide a genuine advantage over classical methods.
Kempf summarizes this as, “the hardness of any computational problem, directly translates into the corresponding widespreadness of entanglement the quantum computer needs to keep track of all the valleys so that it can find the minimum point. Calculational hardness therefore means the need for sophisticated entanglement. Since entanglement is a precious and fragile resource, a hard problem that requires a lot of it can only be solved slowly.”
Entanglement therefore proves to be a useful tool not just for significantly increasing the computational speed of problems but also in characterizing problem difficulty and computation speed. As Gabbassov notes “if we want to devise faster quantum algorithms, we should look not just at the amount of entanglement but also at how this entanglement redistributes/flows” and therefore the structure of the problem. Their work shows that the amount of entanglement used as a resource is more subtle than just providing a general computational speed-up.
Active link Bromo volcano in East Java, Indonesia, which is the most volcanically active country in the world, where heavy rainfall has triggered explosive activity and eruptions at active volcanoes. (Courtesy: iStock/Panya_)
A few years ago, Swiss seismologist Verena Simon noticed a striking shift in the pattern of seismic activity and micro earthquakes in the Mont Blanc region. She found that microquakes in the area, which straddles Switzerland, France and Italy, have fallen into an annual pattern since 2015.
Simon and colleagues at the Swiss Seismological Service in fact found that this annual pattern is linked to heat waves driven by climate change. But they are not the only researchers finding such geophysical links to climate change. There is growing evidence that global warming could cause changes in seismicity, volcanic activity and other such hazards.
In the first eight years from 2006, Simon’s team saw no clear pattern. But then from 2015 they found that seismicity always increases in autumn and stays at a higher level until winter. The researchers wondered if the seasonal pattern was linked to a known increase in meltwater infiltration into the Mont Blanc massif in late summer and autumn every year.
Seasonal seismic trends
Scientists have long known that when water percolates underground it increases the pressure in gaps, or pores, in rocks, which alters the balance of forces on faults, leading to slips – and triggering seismic activity.
In the late 1990s researchers analysed water flow into the 12 km long Mont Blanc tunnel, which links France and Italy (La Houille Blanche86 78). They also found a yearly pattern, with a rapid increase in water entering the tunnel between August and October. The low mineral content of the water and results from tracer tests, using fluorescent dyes injected into a glacier crevasse on the massif, confirmed that this increased flow was fresh water from snow and glacier melt.
To explore the seasonal trend in the water table, Simon and colleagues created a hydrological model (a simplified mathematical model of a real-world water flow system) using the tunnel inflow data; plus metrological, hydrological and snow-pack data from elsewhere in the Alps. They also included information on how water diffuses into rocks, alters pore pressure and increases seismic activity (Earth and Planetary Sci. Lett.666 119372).
Underground menace The Mont Blanc Massif, with Lac Blanc in the foreground. The timing of heatwaves in this region seemingly correlates with increased microquakes. (Courtesy: Shutterstock/Rasto SK)
When combined with their seismicity data, autumn seismic activity appeared to be triggered by spring surface runoff, which arises from melting glacial ice and snow. The exact timing depends on the depth of the microquakes, with shallow quakes being linked to surface runoff from the previous year, while there is a two-year delay between runoff and deeper quakes. Essentially, their work found a link between meltwater and seismic activity in the Mont Blanc massif; but it could not explain why the autumn increase in microquakes only started in 2015.
Perhaps the answer lies in historic meteorological data of the area. In 2015 the Alps experienced a prolonged, record-breaking heatwave, which led to very many high-altitude rockfalls in a number of areas, including in the Mont Blanc massif, as rock-wall permafrost warmed. Data also show that since then there has been a big increase in days when the average temperatures in the Swiss Alps is above 0 °C. These so-called “positive degree days” are known to lead to increased glacial melt.
All of these findings support the idea that the onset of seasonal seismic activity is linked to climate change-induced increases in meltwater and alterations in flow paths. Simon explains that rock collapses can alter the pathways that water follows as it infiltrates into the ground. Combined with increases in meltwater, this can lead to pore-pressure changes that increase seismicity and trigger it in new places.
These small earthquakes in the Mont Blanc massif are unlikely to trouble local communities. But the researchers did find that at times the seismic hazard – an indicator of how often and intensely the earth could shake in a specific area – rose by nearly four orders of magnitude, compared with pre-2015 level. They warn that similar processes in glaciated areas that experience larger earthquakes than the Alps, such as the Himalayas, might be less gentle.
Extreme rainfall
Climate change is also altering water-flow patterns by increasing the intensity of extreme weather events and heavy rainfall. And there is already evidence that such extreme precipitation can influence seismic activity.
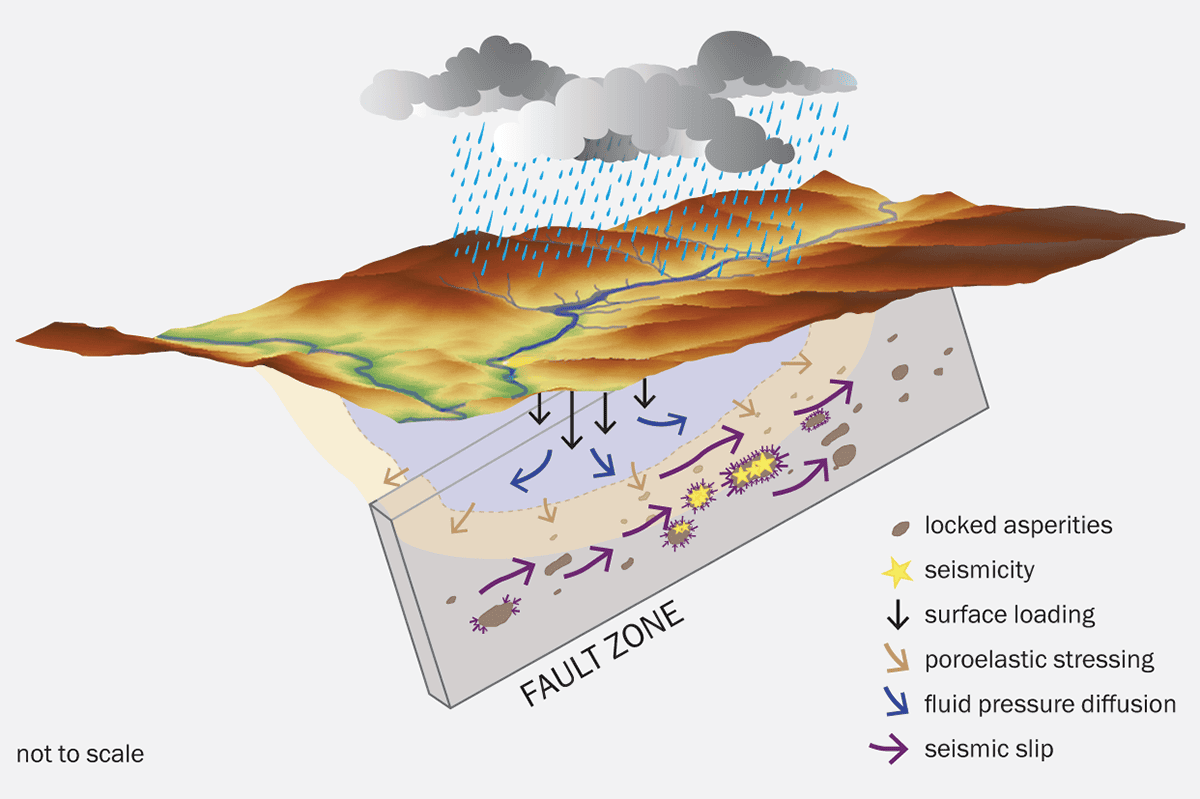
In 2020 Storm Alex brought record-breaking rainfall to the south-east of France, with some areas seeing more than 600 mm in 24 hours. In the following 100 days 188 earthquakes were recorded in the Tinée valley, in south-eastern France. Although all were below two in magnitude, that volume of microquakes would usually be spread over a five-year period in the region. A 2024 analysis carried out by seismologists in France concluded that increased fluid pressure from the extreme rainfall caused a stressed fault system to slip, initiating a seismic swarm – a localized cluster of earthquakes, without a single “mainshock”, that take place over a relatively short period of days, months or years (see figure 1).
French seismologist Laeticia Jacquemond and colleagues have developed a model showing the sequence of mechanisms that likely trigger a seismic swarm, which is a localized cluster of earthquakes. The sequence starts with abrupt and extreme rainfall, like 2020’s Storm Alex. Thanks to open fault zones, a lot of rainfall is transmitted deep within a critically stressed crust. The fluid invasion through the fractured medium then induces a poroelastic response of the crust at shallow depths, triggering or accelerating a seismic slip on fault planes. As this slip propagates through the fault network, it pressurizes and stresses locked asperities (areas on an active fault where there is increased friction), predisposed to rupture, and initiates a seismic swarm.
There have been other examples in Europe of seismic activity linked to extreme rainfall. For instance, in September 2002 a catastrophic storm in western Provence in southern France, with similar rainfall levels as Storm Alex, triggered a clear and sudden increase in seismic activity, a study concluded. While another analysis found that an unusual series of 47 earthquakes over 12 hours in central Switzerland in August 2005 was likely caused by three days of intense rainfall.
According to Marco Bohnhoff from the GFZ Helmholtz Centre for Geosciences in Potsdam, Germany, the link between fluid infiltration into the ground and seismicity is well understood – from fluid injection for oil and gas production, to geothermal development and heavy rainfall. “The pore pressure is increased if there is a small load on top, enforced by water, and that changes the pressure conditions in the underground, which can release energy that is already stored there,” Bohnhoff explains.
Pressure conditions Scientists have tracked the change in water level in the reservoir behind the four dams that make up the Koyna hydroelectric project in Maharashtra, India, finding that the rise during monsoon season is accompanied by an increase in seismic activity over the same period. (Courtesy: iStock/yogesh_more)
A good example of this is the Koyna Dam, one of India’s largest hydroelectric projects, which consists of four dams. Every year during the monsoon season the water level in the reservoir behind the dams increases by about 20–25 m, and with this comes an increase in seismic activity. “After the rain stops and the water level decreases, the earthquake activity stops,” says Bohnhoff. “So, the earthquake activity distribution nicely follows the water level.”
Rising seas and seismic activity
According to Bohnoff, anything that increases the pressure underground could trigger earthquakes. But he has also been studying the effect of another consequence of climate change: sea-level rise.
Undisputed and accelerating, sea-level rise is driven by two main effects linked to climate change: the expansion of ocean waters as they warm, and the melting of land ice, mainly the Antarctic and Greenland ice sheets. According to the World Meteorological Organization, sea levels will rise by half a metre by 2100 if emissions follow the Paris Agreement, but increases of up to two metres cannot be ruled out if emissions are even higher.
As ocean waters increase, so does the load on the underground. “This will change the global earthquake activity rate,” says Bohnhoff. In a study published in 2024, Bohnhoff and colleagues found that sea-level rise will advance the seismic clock, leading to more and in some cases stronger earthquakes (Seismological Research Letters95 2571).
“It doesn’t mean that all of a sudden there will be earthquakes everywhere, but earthquakes that would have occurred sometime in the future will occur sooner,” he says. “We’re changing the regularity of earthquakes.” The risk created by this is greatest in coastal mega-cities, located near critical fault zones, such as San Francisco and Los Angeles in the US; Istanbul in Turkey; and Tokyo and Yokohama in Japan.
The findings cannot be used to predict individual earthquakes – in fact, it is very difficult to predict how much the seismic clock will advance, as it depends on the amount of sea-level rise. But there are faults around the world that are critically stressed and close to the end of their seismic cycle.
“Faults that are very, very close to failure, where basically there would be an earthquake, say in 100 years or 50 years, they might be advanced and that might occur very soon,” he explains.
Between a rock and a hard place
Another significant geological hazard linked to climate change and heavy rainfall is volcanic activity. In December 2021 there was devastating eruption of Mount Semeru, on the Indonesian island of Java. “There was a really heavy rainfall event and that caused the collapse of the lava dome at the summit,” says Jamie Farquharson, a volcanologist at Niigata University in Japan.
This led to a series of eruptions, pyroclastic flows and “lahars” – devastating flows of mud and volcanic debris – that killed at least 69 people and damaged more than 5000 homes. Although it is challenging to attribute this specific event to climate change, Farquharson says that it is a good example of how global warming-induced heavy rainfall could exacerbate volcanic hazards.
Farquharson and colleagues noticed links between ground deformations and rainfall at several volcanoes. “We started seeing some correlations and thought why shouldn’t we? Because from a rock mechanics point of view, these volcanoes would be more prone to fracturing and other kinds of failure when the pore pressure is high,” says Farquharson. “And one of the easiest ways of increasing pore pressure is by dumping a load of rain onto the volcano.”
Such rock fracturing can open new pathways for magma to propagate towards the surface. This can happen deep underground, but also near the surface, for instance by causing a chunk of the flank to slide off a volcano. As with earthquakes, these changes could alter the timing of eruptions. For volcanoes that might be primed for an eruption, where the magma chamber is inflating, extreme rainfall events might hasten an eruption. But as Farquharson explains, such rainfall events “could bring something that was going to happen at an unspecified point in the future across a tipping point”.
A few years ago Farquharson, together with atmospheric scientist Falk Amelung of the University of Miami in the US, published a study showing that if global warming continues at current rates, rainfall-linked volcanic activity – such as dome explosions and flank collapses – will increase at more than 700 volcanoes around the globe (R. Soc. Open Sci.9 220275).
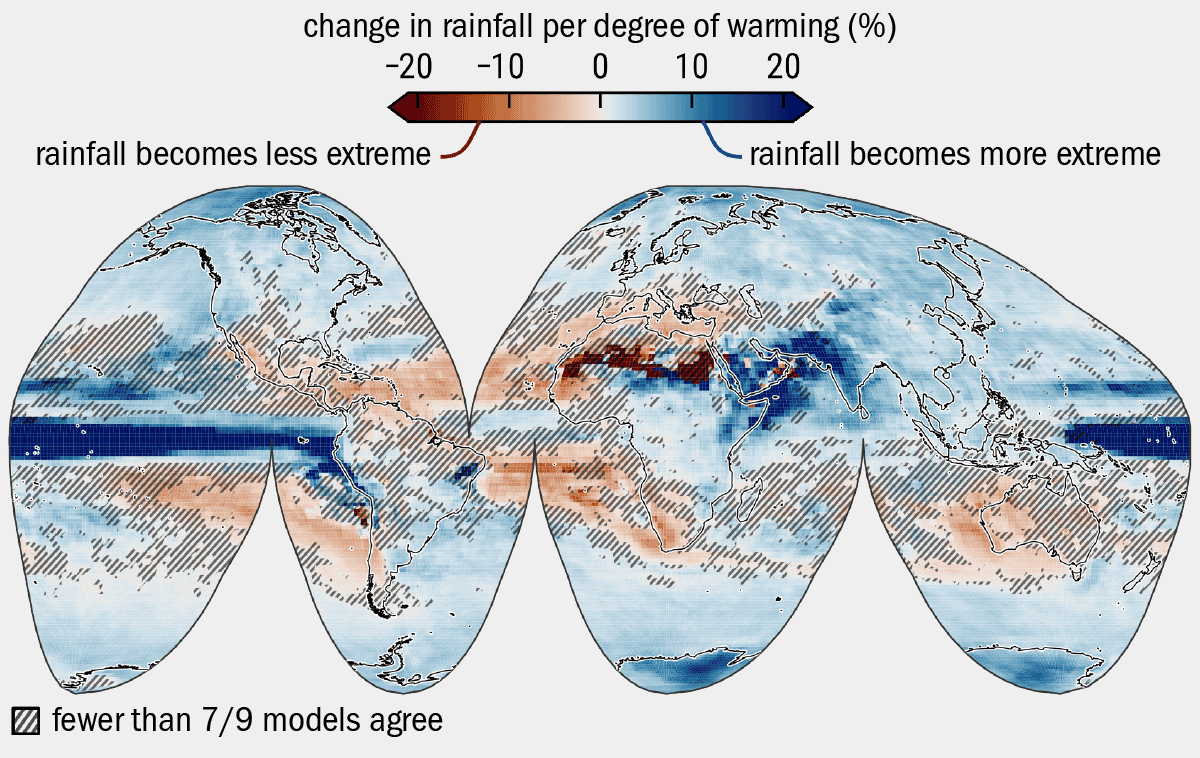
To explore the impact of rainfall, Farquharson and Amelung analysed decades of reports on volcanic activity from the Smithsonian’s Global Volcanism Program. This showed that heavy or extreme rainfall has been linked to eruptions and other hazards, such as lahars at at least 174 volcanoes (see figure 2).
There are 1234 volcanoes on land that have been active in the Holocene, the current geological epoch, which began around 12,000 years ago. The geologists used nine different models to explore how climate change might alter rainfall at these volcanos. They found that 716 of these volcanoes will experience more extreme rainfall as global temperatures continue to rise. The models did not agree on whether rainfall will become more or less extreme at 407 of the volcanoes, and the remaining 111 are in regions expected to see a drop in heavy rain.
Jamie Farquharson and colleagues are studying how heavy rainfall drives a range of volcanic hazards. The colours on the map reflect the “forced model response” (FMR) – the percentage change of heavy precipitation for a given unit of global warming. Serving as a proxy for the likelihood of extreme rainfall events, the value of FMR was averaged from nine different “general circulation models” (i.e. global climate models). FMR is shown here as the percentage rise or fall in extreme rainfall projected by the models for every degree of global warming between 2005 and 2100 CE. The darkest reds show areas that will experience a 20% or more decrease in extreme rainfall for each degree of warming, while the darkest blues highlight areas which will experience a 20% or more increase in extreme rainfall per degree of warming. The figures were made with CMIP5 model data, which assumes a “high emissions” scenario. Their results suggest that if global warming continues unchecked, the incidence of primary and secondary rainfall-related volcanic activity – such as dome explosions or flank collapse – will increase at more than 700 volcanoes around the globe.
Volcanic regions where heavy rainfall is expected to increase include the Caribbean islands, parts of the Mediterranean, the East African Rift system, and most of the Pacific Ring of Fire.
In fact, volcanic hazards in many of these regions have already been linked to heavy rainfall. For instance, in 1998 extreme rainfall in Italy led to devastating debris flows on Mount Vesuvius and Campi Flegrei, near Naples, killing 160 people.
Elsewhere, rainfall has sparked explosive activity at Mount St Helens, in the Cascade Mountains of Canada and the western US. Other volcanoes in this range, which is part of the Ring of Fire, put major population centres at significant lahar risk, due to their steep slopes. In both the Caribbean and Indonesia – the world’s most volcanically active country, heavy rainfall has triggered explosive activity and eruptions at active volcanoes.
Farquharson and Amelung warn that if heavy rainfall increases in these regions as predicted, it will heighten an already considerable threat to life, property and infrastructure. As we enter a new era of much higher resolution climate modelling, Farquharson hopes that we will “be able to get a much better handle on exactly which [volcanic] systems could be affected the most”. This may enable scientists to better estimate how hazards will change at specific geographical locations.
Fire and ice
Scientists are also concerned about what will happen to volcanoes currently buried under ice as the climate warms.Through modelling work and studying volcanoes that sat below the Patagonian Ice Sheet during and at the end of the last ice age, Brad Singer, a geoscientist at the University of Wisconsin-Madison in the US, and colleagues have been exploring the impact of deglaciation on volcanic processes.
They found that ice loss can lead to an increase in large explosive eruptions. This occurs because as the ice melts, the weight on the volcano drops, which allows magma to expand and put pressure on the rock within the volcano. Also, as pressure from the ice reduces, dissolved volatile gases like water and carbon dioxide separate from the magma to form gas bubbles. This further increases the pressure in the magma chamber, which can promote an eruption.
But each volcano responds differently to ice. Singer’s team has been dating and studying the chemical composition of lava flow samples from South America, to track the behaviour of volcanoes over tens of thousands of years, through the build-up of the ice and after deglaciation.
The Patagonian Ice Sheet began to melt very rapidly about 18,000 years ago and by about 16,000 years ago it was gone. “We develop a timeline and put compositions on that timeline and look to see if there were any changes in the composition of the magmas that were erupting as a function of the thickness of the ice sheet,” explains Singer. “We are finding some really interesting things.”
The Puyehue-Cordón Caulle and Mocho-Choshuenco volcanic complexes in southern Chile both erupt rhyolitic magmas. But they were not producing this type of magma before the ice retreated, as Singer and colleagues found (GSA Bulletin136 5262) (see figure 3).
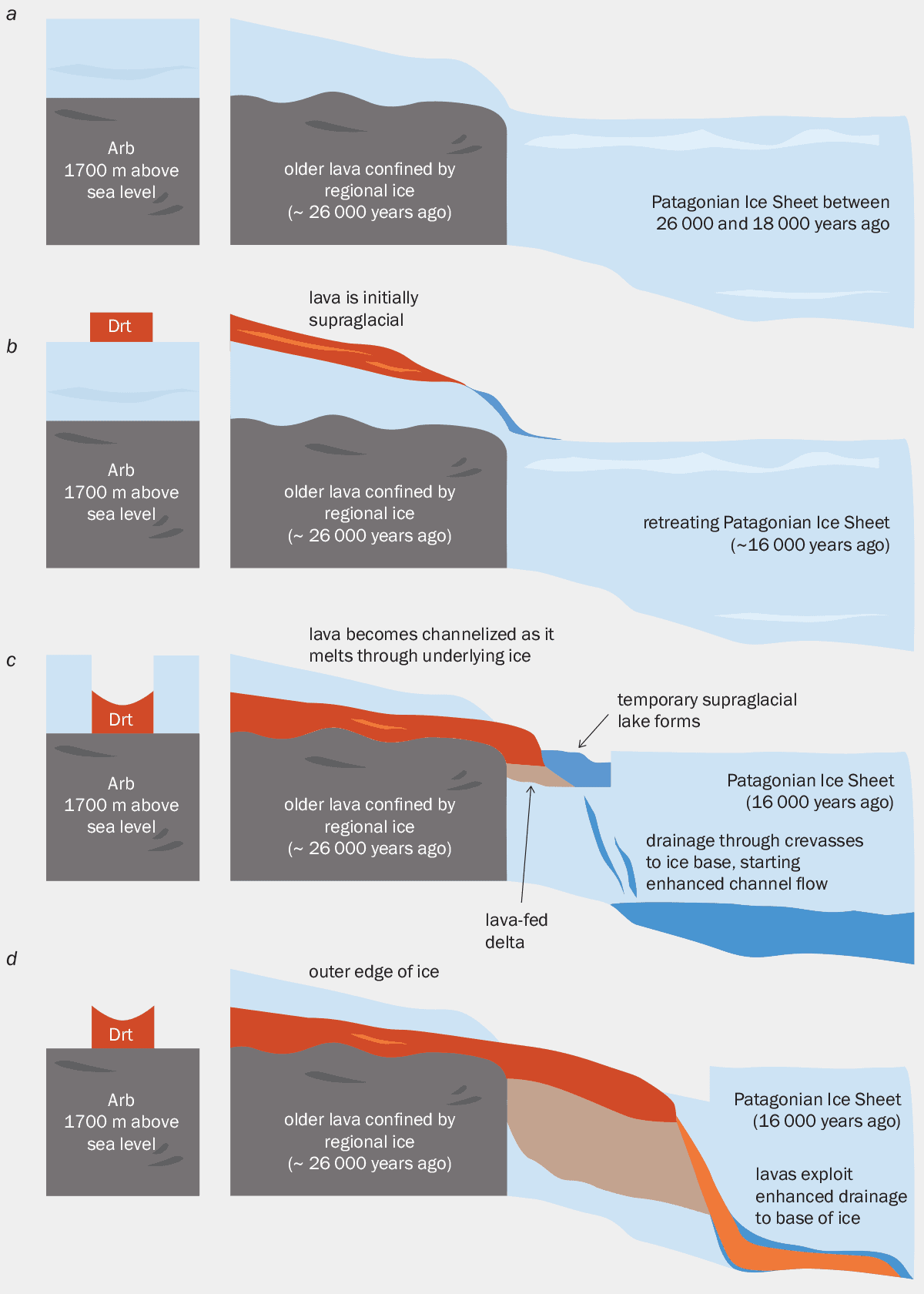
Geologist Brad Singer and colleagues are studying how glaciers and ice sheets impact the evolution of volcanoes, to develop a “lava-fed delta” model. (a) The researchers studied basaltic andesites in the Río Blanco river in Argentina (Arb). A fine-grained extrusive igneous rock that forms when volcanic magma erupts and crystallizes outside of the volcano, basaltic andesites were impounded by the Patagonian Ice Sheet roughly 26,000 years ago. Here they formed cliffs that were then occupied by the Patagonian Ice Sheet at 1500–1700 m above sea level between 26,000 and 20,000 years ago. Ice on top of the edifice should have been comparatively thinner than in the surrounding valleys. (b) As the ice sheet retreated between 18,000 and 16,000 years ago, dacite – a fine-grained volcanic rock formed by rapid solidification of lava that is high in silica and low in alkali metal oxides – from the Río Truful river in Chile (Drt) flowed onto it. (c) Lava is channelized as it melts the ice to form a lava-fed delta. (d) Dacite flows through the ice and to its base.
“We don’t know for sure that [magma change] is attributable to the glaciation, but it is curious that immediately following the deglaciation we start to see the first appearance of these highly explosive rhyolitic magmas,” says Singer. The volcanologists suspect that the ice sheet reduced eruptions at these volcanos, leading magma to accumulate over thousands of years. “That accumulated reservoir can evolve into this explosive dangerous magma type called rhyolite,” Singer adds.
But that didn’t always happen. The Calbuco volcano, in southern Chile, has always erupted andesite, an intermediate-composition magma. “It’s never erupted basalt, it’s never erupted rhyolite, it’s erupting andesite, regardless of whether the ice is there or not,” explains Singer.
There are also differences in how quickly volcanoes reacted to the deglaciation. At Mocho-Choshuenco, for example, there was a large rhyolite eruption about 3000 years after the loss of ice. Singer suspects that the delay “reflects the time that it took to exsolve the volatiles from the rhyolite”. But at the nearby, very active Villarrica volcano, there was no such delay. It experienced a huge eruption 16,800 years ago, almost immediately after the ice disappeared.
Melting ice sheets
Volcanic activity from melting ice sheets, due to current climate change, is probably not a direct hazard to people. But below the West Antarctic Ice Sheet sits the West Antarctic Rift – a system that is thought to contain at least 100 active volcanoes.
A major contributor to global sea-level rise, the West Antarctic Ice Sheet is particularly vulnerable to collapse as temperatures rise. If they become more active and explosive, the volcanoes of the West Antarctic Rift System could accelerate ice melting and sea-level rise.
Icy danger Thwaites Glacier (photographed by the Copernicus Sentinel-2 satellite in 2019) is a tongue of the West Antarctic Ice Sheet and has so much ice that it alone could raise global sea levels by around 60 cm. The ice sheet sits on top of a rift system thought to contain 100 active volcanoes. Reduced ice load as the sheet melts could trigger these volcanoes, which would in turn accelerate melting. (CC BY-SA 3.0 IGO/ESA)
“The melting of the West Antarctic Ice Sheet could remove the surface load that’s preventing eruptions from occurring,” says Singer. Such eruptions could bring lava and heat to the base of the ice sheet, which is dangerous because melting at the base can cause the ice to move faster into the ocean. The resulting rising sea levels could go on to advance the seismic clock and trigger earthquakes.
In the long run, increased volcanic activity will impact global climate, with the cumulative effect of multiple eruptions contributing to global warming thanks to a build-up of greenhouse gases. Essentially, a positive feedback loop is created, as melting ice caps, helped by volcanoes, could lead to more earthquakes. Managing the Earth’s warming and protecting the world’s remaining glaciers and ice sheets is therefore more crucial than ever.
The near and far sides of the Moon are very different in their chemical composition, their magmatic activity and the thickness of their crust. The reasons for this difference are not fully understood, but a new study of rocks brought back to Earth by China’s Chang’e-6 mission has provided the beginnings of an answer. According to researchers at the Chinese Academy of Sciences (CAS) in Beijing, who measured iron and potassium isotopes in four samples from the Moon’s gigantic South Pole-Aitken Basin (SPA), the discrepancy likely stems from the giant meteorite impact that created the basin.
China has been at the forefront of lunar exploration in recent years, beginning in 2007 with the launch of the lunar orbiter Chang’e-1. Since then, it has carried out several uncrewed missions to the lunar surface. In 2019, one of these, Chang’e-4, became the first craft to touch down on the far side of the Moon, landing in the SPA’s Von Kármán crater. This 2500-km-wide feature extends from the near to the far side of the Moon and is one of the oldest known impact craters in our solar system, with an estimated age of between 4.2 and 4.3 billion years old.
Next in the series was Chang’e-5, which launched in November 2020 and subsequently returned 1.7 kg of samples from the near side of the Moon – the first lunar samples brought back to Earth in nearly 50 years. Hot on the heels of this feat came the return of samples from the far side of the Moon aboard Chang’e-6 after it launched on 3 May 2024.
A hypothesis that aligns with previous results
When scientists at the CAS Institute of Geology and Geophysics and colleagues analysed these samples, they found that the ratio of potassium-41 to potassium-39 is greater in the samples from the SPA basin than in samples from the near side collected by Chang’e-5 and NASA’s Apollo missions. According to study leader Heng-Ci Tian, this potassium isotope ratio is a relic of the giant impact that formed this basin.
Tian explains that the impact created such intense temperatures and pressures that many of the volatile elements in the Moon’s crust and mantle – including potassium – evaporated and escaped into space. “Since the lighter potassium-39 isotope would more readily evaporate than the heavier potassium-41 isotope, the impact produced this greater ratio of potassium-41 to potassium-39,” says Tian. He adds that this explanation is also supported by earlier results, such as Chang’e 6’s discovery that the mantle on the far side contains less water than the near side.
Before drawing this conclusion, the researchers, who report their work in the Proceedings of the National Academy of Sciences, needed to rule out several other possible explanations. The options they considered included whether irradiation of the lunar surface by cosmic rays could have produced an unusual isotopic ratio, and whether magma melting, cooling and eruptive processes could have changed the composition of the basaltic rocks. They also examined the possibility that contamination from meteorites could be responsible. Ultimately, though, they concluded that these processes would have had only negligible effects.
The effects of the impact
Tian says the team’s work represents the first evidence that an impact event of this size can volatilize materials deep within the Moon. But that’s not all. The findings also offer the first direct evidence that large impacts play an important role in transforming the Moon’s crust and mantle. Fewer volatiles, for example, would limit volcanic activity by suppressing magma formation – something that would explain why the lunar far side contains so few of the vast volcanic plains, or maria, that appear dark to us when we look at the Moon’s near side from Earth.
“The loss of moderately volatile elements – and likely also highly volatile elements – would have suppressed magma generation and volcanic eruptions on the far side,” Tian says. “We therefore propose that the SPA impact contributed, at least partially, to the observed hemispheric asymmetry in volcanic distribution.”
Technical challenges
Having hypothesized that moderately volatile elements could be an effective means of tracing lunar impact effects, Tian and colleagues were eager to use the Chang’e-6 samples to investigate how such a large impact affects the shallow and deep lunar interior. But it wasn’t all smooth sailing. “A major technical challenge was that the Chang’e‑6 samples consist mainly of fine-grained materials, making it difficult to select large individual grains,” he recalls. “To overcome this, we developed an ultra‑low‑consumption potassium isotope analytical protocol, which ultimately enabled high‑precision potassium isotope measurements at the milligram level.”
The current results are preliminary, and the researchers plan to analyse additional moderately volatile element isotopes to verify their conclusions. “We will also combine these findings with numerical modelling to evaluate the global-scale effects of the SPA impact,” Tian tells Physics World.
Chimoio’s winning entry is an article covering the work of the South African physicist Lindiwe Khumalo, who carries out experiments on quantum sensors in a former gold mine 3 km underground.
Khmalo uses the natural shielding from 3 km of rock to test muon-based sensors and ultra-low-noise interferometric measurements, contributing to dark-matter detection, neutrino studies, and precision metrology.
“It’s a compelling human story about an African physicist working in an extreme environment usually associated with heavy industry, not quantum physics,” says Chimoio, whose article will be published in Physics World soon.
Chimoio is a Zimbabwean-born investigative journalist, now based in South Africa. He specializes in geopolitics, technology, security and socio-economic issues, with some of his writing appearing in Nature Africa and Africa Uncensored.
Adepoju’s winning piece – describing the discovery of large-scale galactic motion using the emission produced by tiny quantum “spin-flips” in hydrogen atoms – is published today in Physics Magazine.
Adepoju is a freelance journalist and podcaster based in Ibadan, Nigeria, whose has written for publications such as Nature, New Scientist, and Scientific American.
In his pitch-winning story, Adepoju describes the recent discovery of rotation within a galaxy-filled filament that stretches over 50 million light years. The cosmic winding, which had never been directly measured in a single filament, was found using hydrogen-emission data from the MeerKAT radio telescope in South Africa and could lead to a new way to probe dark matter.
Physics World and Physics Magazine would like to thank all of the writers who submitted pitches to the contest. We hope that this endeavour will lead to more quantum-inspired stories by science journalists across the world.
A major upgrade to the LHCb experiment at CERN is under threat after the UK did not commit any further contributions towards the project. The decision by the UK Research and Innovation (UKRI) to defund the plan means that unless the decision if overturned, the experiment will now likely finish operation in 2033.
LHCb is one of the four large experiments based at the Large Hadron Collider (LHC) at CERN. It specializes in the measurements of the parameters of charge-parity (CP) violation in the interactions of b- and c-hadrons, studies of which help to explain the matter-antimatter asymmetry in the universe.
LHCb began recording its first data in 2009 when the LHC began operations and started its main research programme from 2010.
At the end of 2018 it was the shut down for upgrades, which were completed in 2022. That led to a vast increase in the amount of data the experiment could collect, allowing significant improvements in precision for many measurements.
The detector is expected to operate until 2033 by which time it would have reached the end of its lifetime after years of intense radiation damage.
LHCb is operated by the LHCb collaboration, which involves about 1700 scientists and technicians from over 100 institutions in 22 countries around the world with work on the machine having already resulted in over 800 publications.
The UK is one of the leading countries working on LHCb – four of the eight spokespeople for the experiment have come from the UK – and over the past decade physicists from the UK have been planning an upgrade to experiment dubbed LHCb upgrade II.
This would take advantage of the upgrade to the LHC – the High-Luminosity LHC (HL-LHC) – and offer an order of magnitude increase in luminosity over upgrade I.
The second upgrade would provide another boost in capability to answer questions such as whether all CP-violation phenomena are consistent with the Standard Model of particle physics or require an extended theory as well as how the strong interaction binds together the exotic tetraquark and pentaquark states that have been discovered by LHCb.
At a cost of about £150m with the construction phase beginning in 2027, the upgrade components would be installed by 2035 before collecting data for five to six years until the HL-LHC is shut down in 2040.
UK researchers submitted a proposal to the UKRI infrastructure fund in 2021 to begin work on the upgrade and was awarded £49.4m in 2022.
Some £5m has been spent on the pre-construction phase, in which agreements have been made with international partners on the scope and design of the improved detector.
Yet on 19 December researchers working on the project were sent a letter telling them that the remaining funding has “not been prioritised” and will now be cancelled.
“It was a complete shock,” says Tim Gershon from the University of Warwick, who is principal investigator for the project in the UK and is set to become spokesperson for the international collaboration in July.
‘Out in the cold’
The Science and Technology Facilities Council’s (STFC) core budget has been held relatively flat from £835m to £842m from 2026 to 2030. Yet the council said that projects would need to be cut given inflation, rising energy costs as well as “unfavourable movements in foreign exchange rates” that have increased STFC’s annual costs by over £50m a year.
The STFC, which is one of the main funding council belonging to UKRI, has already said that it needs to reduce spending from the core budget by at least 30% over 2024/2025 levels at the same time it also announced that it will need to reduce the number of projects that are funded by its infrastructure fund.
It’s like paying to heat your house but then sitting outside in the cold
Tim Gershon
Four projects will now not be prioritised. They include two UK national facilities: the Relativistic Ultrafast Electron Diffraction and Imaging facility and a mass spectrometry centre dubbed C‑MASS.
The other two are international particle-physics projects: the upgrade to LHCb as well as a contribution to the Electron-Ion Collider at the Brookhaven National Laboratory that is currently being built by a collaboration of 40 countries.
“This is more terrible news for physics, for the UK and for global scientific progress. The withdrawal of funding in this abrupt way is incredibly damaging to our international reputation as a science superpower and could cause long-term damage to the UK economy,” notes Paul Howarth, president-elect of the Institute of Physics, which publishes Physics World. “But even more important is the harm this cut will cause to human understanding of the universe and human progress.”
Gershon adds that the LHCb collaboration were not asked for any input before the decision was made and since then they have trying to work out what it means.
“The UK pays the CERN subscription, which pays for the accelerator, but needs to also invest in experiments to obtain scientific return from this,” says Gershon. “It’s like paying to heat your house but then sitting outside in the cold.”
It might be possible to get funding from elsewhere in the short-term to cover the initial work on the upgrade, but Gershon sats that without investment from UKRI/STFC, the project will be dead as it would not be possible for international partners to go ahead without UK involvement on the timescale dictated by the LHC schedule.
That would mean the LHCb stops operating from 2033 and does not take advantage of the HL-LHC. “The move also goes against the European Strategy for Particle Physics roadmap, of which the top priority is fully exploiting the HL-LHC,” says Gershon. “Without LHCb upgrade, it won’t be possible to do that.”
Howarth adds there are “demonstrable impacts on UK growth and prosperity” for such research. “An earlier upgrade to the LHCb experiment generated about £15m in contracts for more than 80 UK companies,” he adds. “This funding cut means the upgrade is unlikely to go ahead, so all this business for UK innovators is lost. We urge the government to step back and consider how its new funding strategy will impact UK science.”
Nothing stays static in today’s job market. Physicist Gabi Steinbach recalls that about five years ago, fresh physics PhDs could snag lucrative data-scientist positions in companies without job experience. “It was a really big boom,” says Steinbach, at the University of Maryland, US. Then, schools started formal data-science programmes that churned out job-ready candidates to compete with physicists. Now, the demand for physicists as data scientists “has already subsided,” she says.
Today, new graduates face an uncertain job market, as companies wrestle with the role of artificial intelligence (AI), and due to the funding cuts of science research agencies in the US. But those with physics degrees should stay optimistic, according to Matt Thompson, a physicist at Zap Energy, a fusion company based in Seattle, Washington.
“I don’t think the value of a physics education ever changes,” says Thompson, who has mentored many young physicists. “It is not a flash-in-the-pan major where the funding and jobs come from changes. The value of the discipline truly is evergreen.”
Evergreen discipline
In particular, a physics degree prepares you for numerous technical roles in emerging industrial markets. Thompson’s company, for example, offers a number of technical roles that could fit physicists with a bachelor’s, master’s or PhD.
A good way to set yourself up for success is to begin your job hunt two years before you expect to graduate, says Steinbach, who guides young researchers in career development. “Many students underestimate the time it takes,” she says.
The early start should help with the “internal” work of job hunting, as Steinbach calls it, where students figure out their personal ambitions. “I always ask students or postdocs, what’s your ultimate goal?” she says. “What industry do you want to work in? Do you like teamwork? Do you want a highly technical job?”
Then, the external job hunt begins. Students can find formal job listings on Physics World Jobs, APS Physics Jobs and in the Physics World Careers and APS Careers guides, as well as companies’ websites or on LinkedIn. Another way to track opportunities is to read investment news, says Monica Volk, who has spent the last decade hiring for companies, including Silicon Valley start-ups. She follows “Term Sheet,” a Fortune newsletter, to see which companies have raised money. “If they just raised $20 million, they’re going to spend that money on hiring people,” she says.
Expert advice From left to right: Gabi Steinbach, Matt Thompson, Monica Volk, Carly Saxton, and Valentine Zatti. (Courtesy: Gabi Steinbach; Zap Energy; Mike Craig; Crouse Powell Photography; Alice & Bob)
Volk encourages applicants to tailor their résumé for each specific job. “Your résumé should tell a story, where the next chapter in the story is the job that you’re applying for,” she says.
Hiring managers want a CV to show that a candidate from academia can “hit deadlines, communicate clearly, collaborate and give feedback.” Applicants can show this capability by describing their work specifically. “Talk about different equipment you’ve used, or the applications your research has gone into,” says Carly Saxton, the VP of HR at Quantum Computing, Inc. (QCI), based in New Jersey, in the US. Thompson adds that describing your academic research with an emphasis on results – reports written, projects completed and the importance of a particular numerical finding – will give those in industry the confidence that you can get something done.
It’s also important to research the company you’re applying for. Generative AI can help with this, says Valentine Zatti, the HR director for Alice & Bob, a quantum computing start-up in France. For example, she has given ChatGPT a LinkedIn page and asked it to summarize the recent news about a company and list its main competitors. She is careful to verify the veracity of the summaries.
When writing a CV , it’s important to use the keywords from the job description. Many companies use applicant-tracking systems, which automatically filter out CV without those keywords. This may involve learning the jargon of the industry. For example, when Thompson looked for jobs in the defence sector, he found out they called cameras “EO/IR,” short for electro-optic infrared instruments. Once he started referring to his expertise using those words, “I got a lot better response,” he says.
Generative AI can also assist you in putting together a résumé. For example, it can make résumés, which should be one page long, more concise, or help you better match your language to the job description. But Steinbach cautions that you must stay vigilant. “If it’s writing things that don’t sound like you, or if you can’t remember what’s written on it, you will fail at your interview,” says Steinbach.
Companies fill job openings quickly, especially right now, so Thompson also recommends focusing on networking.“It’s fine to apply for jobs you see online, but that should be maybe 20 percent of your effort,” he says. “Eighty percent should be talking to people.” One effective approach is through company internships before graduation. “We jump at the opportunity to hire former interns,” says Saxton.
Thompson suggests arranging a half-hour call with someone whose job looks interesting to you. You can find people through your alumni networks, LinkedIn or APS’s Industry Mentoring for Physicists (IMPact) program, which connects students and early-career physicists from any country with industrial physicists worldwide for career guidance. You can also attend career fairs at your university and those
organized by the APS.
Skills showcase
Once a company is interested in you, you can expect several rounds of interviews. The first will be about the logistics of the job – whether you’d need to relocate, for example. After that, for technical roles you can expect technical interviews. Recently, companies have encountered candidates secretively using AI to cheat during these interviews. They may eliminate the candidate for cheating. “If you don’t know how to do something, it’s better to be honest about it than to use AI to get through a test,” says Saxton. “Companies are willing to teach and develop core skills.”
What physics grads use AI tools for in their jobs
(Courtesy: American Institute of Physics)
The“AI Use Among Physics Degree Recipients” report by the American Institute of Physics, published in August 2025, shows how recent physics degree recipients are engaging with AI, encompassing both its development and its application in daily professional activities. New bachelor’s graduates working in both STEM and non-STEM roles who received their degrees between 2023 and 2024 answered whether they routinely used AI tools in their day-to-day work in February 2025.
However, with transparency, showcasing AI skills could be a boon during job interviews. A 2025 survey from the American Institute of Physics found that around one in four students with a physics bachelor’s degree (see the graph) and two in five with physics PhDs routinely use AI for work. The report also found that one in 12 physics bachelor’s degree-earners and nearly one in five physics doctorate-earners who entered the workforce in 2024 have jobs in AI development.
The emerging quantum industry is also a promising job market for physicists. Globally, investors put nearly $2 billion in quantum technology in 2024, while public investments in quantum in early 2025 reached $10 billion. “You’ll have an opportunity to work for companies in their building stage, and you’re able to earn equity as part of that company,” says Saxton.
Alice & Bob are in the midst of hiring 100 new staff, 25 of whom are quantum physicists, including experimentalists and theorists, based in Paris. Zatti, in particular, wants to boost the number of women working in the field.
Currently, the pool of qualified candidates in quantum is small. Consequently, Alice & Bob can screen CVs manually, says Zatti. Both Alice & Bob and US-based QCI say they are willing to hire internationally. QCI is willing to pay legal fees for candidates to help them continue working in the US, says Saxton.
It’s important to stay flexible in today’s job market. “Don’t ignore current trends, but don’t get married to them either,” suggests Steinbach. Thompson agrees, adding that curiosity is key. “You just have to be creative. If you can open your aperture to all of private industry, there’s a lot of opportunity out there.”
Green hydrogen is hydrogen gas produced by splitting water using electrolysis powered entirely by renewable electricity. It is important because it provides a clean fuel option for industries that are very difficult to decarbonise using other methods. Sectors such as steel, cement, glass, and chemicals require extremely high temperatures (1,000–1,600°C), which are hard to achieve reliably or cheaply with electricity alone, so they still rely heavily on fossil fuels.
In this work, the researchers examined whether using green hydrogen actually reduces emissions across different sectors, comparing it not only with fossil fuels but also with other low‑emission alternatives such as heat pumps, electric vehicles, and biofuels. They carried out a prospective life cycle assessment covering all stages of hydrogen (production, transport, and use) using projected 2030 conditions that include cleaner electricity grids, improved electrolyser efficiency, updated industrial processes, and expected hydrogen transport methods. They then compared green hydrogen to alternative technologies across eight applications: producing methanol, ammonia, steel, and aviation fuels; powering fuel‑cell passenger cars; providing low‑temperature domestic heat; supplying high‑temperature industrial heat; and balancing the electricity grid over long periods.
Across all eight applications, green hydrogen produced fewer emissions than fossil fuels, although often only marginally. However, when compared to other low‑emission technologies, green hydrogen often performed similarly or worse. This is because producing and transporting hydrogen still generates emissions, especially when the electricity used is not extremely low‑carbon, and because electrolysis itself is relatively inefficient. Green hydrogen only outperforms other clean options when it is produced using very low‑carbon electricity (such as wind power) and used on‑site without transport. Under these ideal conditions, it becomes the preferred option for ammonia and steel production, industrial and domestic heating, and long‑term grid balancing.
To maximise hydrogen’s climate benefit, emissions must be reduced across the entire supply chain, and hydrogen should be prioritised only in applications where it genuinely outperforms other clean alternatives. The authors propose a climate ladder to help rank and prioritise hydrogen use across sectors, guiding smarter policy and investment decisions.
An unusual signal initially picked up by the LIGO and Virgo gravitational wave detectors and subsequently by optical telescopes around the world may have been a “superkilonova” – that is, a kilonova that took place inside a supernova. According to a team led by astronomers at the California Institute of Technology (Caltech) in the US, the event in question happened in a galaxy 1.3 billion light years away and may have been the result of a merger between two or more neutron stars, including at least one that was less massive than our Sun. If confirmed, it would be the first superkilonova ever recorded – something that study leader Mansi Kasliwal says would advance our understanding of what happens to massive stars at the end of their lives.
A supernova is the explosion of a massive star that occurs either because the star no longer produces enough energy to prevent gravitational collapse, or because it suddenly acquires large amounts of matter from a disintegrating nearby object. Such explosions are an important source of heavy elements such as carbon and iron in the universe.
Kilonovae are slightly different. They occur when two neutron stars collide, producing heavier elements such as gold and uranium. Both types of events can be detected from the ripples they produce in spacetime – gravitational waves – and from the light they give off that propagates across the cosmos to Earth-based observers.
An unusual new kilonova candidate
The first – and so far only – confirmed observation of a kilonova came in 2017 as a result of two neutron stars colliding. This event, known as GW170817, produced gravitational waves that were detected by the Laser Interferometer Gravitational-wave Observatory (LIGO), which is operated by the US National Science Foundation, and by its European partner Virgo. Several ground-based and space telescopes also observed light signals associated with GW170817, which enabled astronomers to build a clear picture of what happened.
Kasliwal and colleagues now believe they have evidence for a second kilonova with a very different cause. They say that this event, initially called ZTF 25abjmnps and then renamed AT2025ulz, could be a kilonova driven by a supernova – something that has never been observed before, although theorists predicted it was possible.
A chain of detections
The gravitational waves from AT2025ulz reached Earth on 18 August 2025 and were picked up by the LIGO detectors in Louisiana and Washington and by Virgo in Italy. Scientists there quickly alerted colleagues to the signal, which appeared to be coming from a merger between two objects, one of which was unusually small. A few hours later, the Zwicky Transient Facility (ZTF) at California’s Palomar Observatory identified a rapidly fading red object 1.3 billion light-years away that appeared to be in the same location as the gravitational wave source.
A few days later, though, something changed. AT2025ulz grew brighter, and telescopes began to pick up hydrogen lines in its light spectra – a finding that suggested it was a Type IIb (stripped-envelope core-collapse) supernova, not a kilonova.
Two possible explanations
Kasliwal, however, remained puzzled. While she agrees that AT2025ulz does not resemble GW170817, she argues that it also doesn’t look like a run-of-the-mill supernova.
In her view, that leaves two possibilities. The first involves a process called fragmentation in which a rapidly spinning star explodes in a supernova and collects a disc of material around it as it collapses. This disc material subsequently aggregates into a tiny neutron star in much the same way as planets form. The second possibility is that a rapidly spinning massive star exploded as a supernova and then split into two tiny neutron stars, both much less massive than our Sun, which later merged. In other words, a supernova may have produced twin neutron stars that then merged to make a kilonova inside it – that is, a superkilonova.
“We have never seen any hints of anything like this before,” Kasliwal says. “It is amazing to me that nature may make tiny neutron stars smaller than a solar mass and more than one neutron star may be born inside a stripped-envelope supernova.”
While Kasliwal describes the data as “tantalizing”, she acknowledges that firm evidence for a superkilonova would require nebular infrared spectroscopy from either the W M Keck Observatory or the James Webb Space Telescope (JWST). On this occasion, that’s not going to be possible, as the event occurred outside JWST’s visibility window and was too far away for Keck to gather infrared spectra – though Kasliwal says the team did get “beautiful” optical spectra from Keck.
The only real way to test the superkilonova theory would be to find more events like AT2025ulz, and Kasliwal is hoping to do just that. “We will be keeping a close eye on any future events in which there are hints that the neutron star is sub-solar and look hard for a young stripped envelope supernova that could have exploded at the same time,” she tells Physics World. “Future superkilonova discoveries will open up this entirely new avenue into our understanding of what happens to massive stars.”
People who teach physics often remove friction from calculations to make life easier for students. While that might speed up someone’s homework, it does mean that this all-important force tends to fade into the background, despite it being crucial for our daily lives. Here to bring friction centre stage is Jennifer Vail, a “tribologist” – or studier of friction – at US firm TA Instruments.
Friction: a Biography is an engaging and wide-ranging book illustrating its many manifestations in the natural world, showing how this force can be harnessed to solve practical engineering problems. Vail, who wrote the book after giving a hugely popular TED talk on friction, does a great job of connecting abstract physical ideas with familiar human experience.
I like, for example, her description of what happens when two surfaces slide over each other but the friction between them isn’t constant. As she explains, this “stick-slip” motion isn’t great if you’re trying to inject a drug into someone with a syringe. But it can be exploited to beautiful effect by violinists, creating “downright lovely” sounds (though apparently not when she’s practising on her own viola).
One of the book’s strengths is its historical context. Famous figures like Leonardo da Vinci are introduced alongside the development of their ideas, lending a human dimension to the science. The author does a great job of explaining how tribology, which comes from the Greek for “to rub”, has been shaped by careful experimentation and the application of rigorous scientific thinking to industrial problems.
After a trip to Switzerland, the physicist Frank Bowden showed we can ski because frictional heating causes a thin layer of snow to melt beneath our skis, providing liquid lubrication.
After a trip to Switzerland, for example, the Australian-born physicist Frank Bowden showed we can ski because frictional heating causes a thin layer of snow to melt beneath our skis, providing liquid lubrication. This overturned an earlier explanation associated with Osborne Reynolds (best known for the eponymous number marking the transition from laminar to turbulent flow) who’d thought that snow melts due to pressure.
Then there is the 19th-century researcher Robert Thurston, whose pendulum experiments on friction in bearings, described here in detail, guided the design of more efficient lubricated systems. As Vail explains, understanding friction is vital in the design of engines, where even small modifications – such as texturing surfaces, adding coatings, or putting nanoparticles into lubricants – can make them much more efficient and extend their useful life.
Historical anecdotes are woven throughout the book. The story of why graphite in pencils came to be called “lead” is particularly memorable. It turns out that the Romans used lead to write, so the name stuck – even after graphite became more popular because it allowed darker writing. There are also lots of excursions into the natural world: did you know that beetles have a protein in their leg joints that acts as a solid lubricant?
Smooth operator
Vail’s discussion of lubrication is clear and well-integrated with practical examples. Particularly insightful is the explanation of how hydrodynamic lubrication occurs in biological systems, such as human cartilage, where a thin fluid layer separates cartilage surfaces in joints, reducing friction and wear. As Vail makes clear, tribology is vital in physiology, for example in how contact lenses work when we blink our eyes or how food feels in our mouth when we chew.
The book also examines fluid dynamics and drag, distinguishing between viscosity as a material property and drag as a force. Vail’s discussion of plaque on the walls of our arteries is particularly compelling. If there’s not enough drag to shear off the plaque it can cause blockages and, potentially, a heart attack – showing how friction plays a role in our health.
Environmental considerations are addressed too. The author discusses, for example, the impact of polytetrafluoroethalyene (PTFE), which she calls “the most controversial solid lubricant ever”. Also known as Teflon, it is widely used in frying pans, but is synthesized using some pretty nasty carcinogenic “forever” chemicals that don’t break down in the environment. PTFE also has a shady past, being first used in the Manhattan atomic-bomb project to coat valves when separating isotopes of uranium.
Friction can improve energy efficiency, reduce greenhouse-gas emissions, and mitigate global warming.
On a more positive note, Vail shows how an understanding of friction can improve energy efficiency, reduce greenhouse-gas emissions, and mitigate global warming. The book extends further still, encompassing atmospheric, oceanic and planetary processes, as well as astronomy and cosmology. Friction is a universal physical principle, extending well beyond conventional engineering applications and broadening the scope of the book.
However, Vail’s intended audience is not always clear. Some sections read like a primer for tribologists, while others are highly speculative, such as the idea that life originated on Earth because oxidized molybdenum was delivered from Mars aboard Martian meteorites. There are also occasional errors and ambiguities, such as her discussion of the subtleties of the Earth’s tides.
Statements such as electric vehicles “consuming 106% energy” could have been more clearly explained, while her market estimate for anti-friction coatings of just over $1.5m by 2028 is almost certainly too low by three orders of magnitude. While these issues do not undermine the book’s scientific substance, they may distract careful readers, and the rapid movement between topics occasionally disrupts the narrative flow.
Overall, though, Vail does a good job of balancing technical exposition with anecdote and gentle humour. Friction might seem an unpromising subject for a book, but non-expert readers will find much to surprise and engage them. Despite its flaws, I would recommend it as an illuminating, if imperfect, celebration of friction and its central role in science and engineering.
A passive vacuum pump that uses 3D-printed surfaces to better absorb gas molecules has been unveiled by researchers in the UK. It removes gas nearly four-times faster than a similar system with a flat surface. The pump could make it easier to design quantum sensors that require high-vacuum conditions.
Cold atoms are at the heart of many quantum-sensing technologies. For example, atom interferometry is used to measure tiny deviations in local gravity – which can be used to map underground infrastructure.
Cold-atom systems must operate at high vacuum and most vacuum pumps are mechanical or electrical in nature. The size of these active pumps and the energy that they consume makes it difficult to operate sensors in remote or mobile scenarios – particularly on satellites. As a result, researchers who are designing quantum sensors are keen on reducing or even eliminating their reliance on active pumps.
One solution is the use of passive pumps, which have surfaces made from materials that absorb large numbers of gas molecules. Now, Lucia Hackermueller and colleagues at the University of Nottingham, Torr Scientific and Metamorphic Additive Manufacturing have created two new textured surfaces that accelerate passive pumping.
Bounce optimization
One of their surfaces is a hexagonal array of tapered pockets that resembles a honeycomb. The other surface is a hexagonal array of conical protrusions. They chose their designs after doing Monte Carlo computer simulations of how gas molecules behave near textured surfaces. When a molecule collides with a flat surface it will either be absorbed or bounce off the surface and escape. However, if the surface has 3D structures on it, a molecule may ricochet back and forth several times between structures before it escapes. Each collision increases the chance that the molecule will be absorbed by the surface. So, the researchers sought to optimize the number of bounces in their simulations.
They then used the 3D printing of a titanium alloy to create the two promising designs on hockey-puck sized flanges that could be installed in a conventional high-vacuum system (see figure). The final step in the fabrication process was to coat the surfaces with a nonevaporable getter, which is a material designed specifically to absorb gas molecules in a vacuum system.
The team found that their hexagonal-pocket design pumped gas 3.8 times faster than a flat surface – and the hexagonal-protrusion design achieved a performance that is nearly as good.
Team member Ben Hopton at the University of Nottingham says, “What’s exciting about this work is that relatively simple surface engineering can have a surprisingly large effect. By shifting some of the burden from active pumping to passive surface-based pumping, this approach has the potential to significantly reduce, or even remove, the need for bulky pumps in some vacuum systems, allowing quantum technologies to be far more portable.”
A new way of creating arrays of ultracold neutral atoms could make it possible to build quantum computers with more than 100,000 quantum bits (qubits) – two orders of magnitude higher than today’s best machines. The approach, which was demonstrated by physicists at Columbia University in the US, uses optical metasurfaces to generate the forces required to trap and manipulate the atoms. According to its developers, this method is much more scalable than traditional techniques for generating arrays of atomic qubits.
“Neutral atom arrays have become a leading quantum technology, notably for quantum computing, where single atoms serve as qubits,” explains atomic physicist Sebastian Will, who co-led the study with his Columbia colleague Nanfang Yu. “However, the technology available so far to make these arrays limits array sizes to about 10,000 traps, which corresponds to a maximum of 10,000 atomic qubits.”
Building on a well-established technique
In common with standard ways of constructing atomic qubit arrays, the new method relies on a well-established technique known as optical tweezing. The principle of optical tweezing is that highly focused laser beams generate forces at their focal points that are strong enough to trap individual objects – in this case, atoms.
To create many such trapping sites while maintaining tight control of the laser’s light field, scientists typically use devices called spatial light modulators (SLMs) and acousto-optic deflectors (AODs) to split a single moderately intense laser beam into many lower-intensity ones. Such arrays have previously been used to trap thousands of atoms at once. In 2025, for example, researchers at the California Institute of Technology in the US created arrays containing up to 6100 trapped atoms – a feat that Will describes as “an amazing achievement”.
A superposition of tens of thousands of flat lenses
In the new work, which is detailed in Nature, Will, Yu and colleagues replaced these SLMs and AODs with flat optical surfaces made up of two-dimensional arrays of nanometre-sized “pixels”. These so-called metasurfaces can be thought of as a superposition of tens of thousands of flat lenses. When a laser beam hits them, it produces tens of thousands of focal points in a unique pattern. And because the pixels in the Columbia team’s metasurfaces are smaller than the wavelength of light they are manipulating (300 nm compared to 520 nm), Yu explains that they can use these metasurfaces to generate tweezer arrays directly, without the need for additional bulky and expensive equipment.
The Columbia researchers demonstrated this by trapping atoms in several highly uniform two-dimensional (2D) patterns, including a square lattice with 1024 trapping sites; patterns shaped like quasicrystals and the Statue of Liberty with hundreds of sites; and a circle made up of atoms spaced less than 1.5 microns apart. They also created a 3.5 mm diameter metasurface that contains more than 100 million pixels and used it to generate a 600 × 600 array of trapping sites. “This is two orders of magnitude beyond the capabilities of current technologies,” Yu says.
Another advantage of using metasurfaces, Will adds, is that they are “extremely resilient” to high laser intensities. “This is what is needed to trap hundreds of thousands of neutral atom qubits,” he explains. “Metasurfaces’ laser power handling capabilities go several orders of magnitude beyond the state of the art with SLMs and AODs.”
Laying the groundwork
For arrays of up to 1000 focal points, the researchers showed that their metasurface-generated arrays can trap single atoms with a high level of control and precision and with high single-atom detection fidelity. This is essential, they say, because it demonstrates that the arrays’ quality is high enough to be useful for quantum computing.
While they are not there yet, Will says that the metasurface atomic tweezer arrays they developed “lay the critical groundwork for realizing neutral-atom quantum computers that operate with more than 100,000 qubits”. These high numbers, he adds, will be essential for realizing quantum computers that can achieve “quantum advantage” by outperforming classical computers. “The large number of qubits also allows for more ‘redundancy’ in the system to realize highly-efficient quantum error correction codes, which can make quantum computing – which is usually fragile – more resilient,” he says.
The Columbia team is now working on further improving the quality of their metasurfaces. “On the atomic arrays side, we will now try to actually fill such arrays with more than 100 000 atoms,” Will tells Physics World. “Doing this will require a much more powerful laser than we currently have, but it’s in a realistic range.”
This episode of the Physics World Weekly podcast features Amanda Randles, who is a computer scientist and biomedical engineer at Duke University in the US. In a conversation with Physics World’s Margaret Harris, Randles explains how she uses physics-based, computationally intensive simulations to develop new ways to diagnose and treat human disease. She has also investigated how data from wearable devices such as smartwatches can be used identify signs of heart disease.
In 2024, the Association for Computing Machinery awarded Randles its ACM Prize in Computing for her groundbreaking work. Harris caught up with Randles at the 2025 Heidelberg Laureate Forum, which brings prizewinning researchers and early-career researchers in computer science and mathematics to Heidelberg, Germany for a week of talks and networking.
Randles began her career as a physicist and she explains why she was drawn to the multidisciplinary research that she does today. Randles talks about her enduring love of computer coding and also reflects on what she might have done differently when starting out in her career.