Durant l’été 2023, l’application mobile Carte Vitale (développé par le GIE SESAM-Vitale pour le compte de l’Assurance Maladie) a été lancé dans huit départements. Elle s’est ouverte à 23 départements en mai 2024, et désormais à l’ensemble du territoire, comme l’indique iGeneration.
La bascule était attendue et même annoncée par le GIE SESAM-Vitale : « courant mars, l’appli carte Vitale sera généralisée à l’ensemble du territoire pour les assurés disposant d’une carte d’identité nationale au nouveau format, grâce à un parcours d’activation simplifié via France Identité ».
La carte Vitale dispose pour rappel de sa propre application. Sur Android, c’est la mise à jour déployée le 3 mars qui active cette fonctionnalité selon les notes de version, tandis que sur iOS, c’est la mouture 5.12.2 du 11 mars. Il est aussi question d’une « ergonomie optimisée » dans les deux cas.
L’Assurance Maladie invite « les praticiens à se rapprocher dès maintenant de l’éditeur de leur logiciel de facturation, qui les accompagneront dans le choix et l’installation de leur matériel de lecture ».
L’Inserm vient de donner des détails sur son programme Impact Santé, financé par France 2030 avec 30 millions d’euros. Le but ? « Détecter en amont les recherches qui pourraient générer des innovations de rupture et à fort impact ».
L’Institut national de la santé et de la recherche médicale a sélectionné quinze projets, dont AIR-MT de Bruno Canard, directeur de recherche au CNRS (laboratoire Architecture et fonction des macromolécules biologiques). C’est un des neuf projets d’accélération, qui ont quasiment tous eu 3 millions d’euros. Il y a aussi six projets d’exploration, avec 150 000 euros à chaque fois.
Si nous parlons d’AIR-MT, c’est que le projet a un pied dans le numérique et l’IA plus particulièrement. En effet, son ambition générale : « développer des méthyltransférases d’ARN (RMTases) via l’IA pour stabiliser et optimiser les ARN messagers (ARNm), ouvrant la voie à des applications révolutionnaires en biologie médicale et biothérapies ».
Autre présentation plus détaillée dans ce document : « Tirer parti des immenses possibilités des ARNm en maîtrisant leur modification (méthodes de « réécriture ») et en surveillant leurs effets (systèmes de « lecture »), pour concevoir des vaccins et thérapeutiques ARN innovants ».
Dans le début des années 2000 (et même avant pour certains), le web francophone disposait d’une large panoplie de sites parlant de hardware. Aujourd’hui, la plupart ont fermé ou ont changé leur fusil d’épaule, certains domaines ont été rachetés pour surfer sur la gloire (du référencement) d’antan afin de diffuser à tout va du contenu généré par des intelligences artificielles.
Cet édito résonne, une fois encore, en écho à mon expérience personnelle. Dans les commentaires sur l’enquête de Jean-Marc, la question a été posée des rédacteurs de certains médias utilisant l’intelligence artificielle pour tout ou partie de leurs contenus. On me retrouvait notamment dans la liste de ceux de 59 Hardware. À raison, j’ai commencé mon aventure dans les médias par ce site, dans les années 2000, bien avant de devenir journaliste (un peu par surprise).
59 Hardware, Matbe et TTH : du hardware à… la GenAI
Comme bien d’autres, 59 Hardware n’a plus rien à voir avec ce qu’il était à la « grande époque », toute proportion gardée bien évidemment. Son nom n’était rien de plus que l’assemblage du numéro de département du Nord (nous étions tous dans les environs de Lille) et du mot Hardware.
Fini les actualités et surtout les tests sur les cartes mères, les processeurs, les cartes graphiques et tout ce qui était stockage. Place maintenant aux contenus générés par IA. Bref, il n’a plus rien à voir avec ce qu’il était auparavant. Il s’agit simplement de récupérer un nom de domaine « connu » par Google (News), avec des liens externes provenant de nombreux sites. Tout le contenu de l’époque semble avoir disparu. Si je suis encore crédité comme rédacteur, aucun de mes contenus n’est accessible.
D’autres sites autour du hardware ont connu la même fin tragique. Il y a évidemment Matbe de Stéphane Charpentier (anciennement materiel.be, après avoir été un blog personnel sur la carte mère K7S5A d’ECS). C’était à l’époque un concurrent et un confrère. Comme 59 Hardware, le site n’affiche désormais plus que des contenus générés par IA.
Dans les sites que les vieux de la vieille connaissent certainement, il y a également TT-Hardware, de Pascal Thevenier. Le site parlait hardware, avec une spécialité sur les ordinateurs portables. Il quitte l’aventure en 2015 suite à des soucis avec son ex-employeur (Rue du Commerce, désormais propriété de LDLC).
Il en a lancé un autre, TTH-News.be, mais qui ferme au bout de quelques années. Depuis, TT-Hardware est de nouveau en ligne, mais là encore sans rapport avec ce qu’il était avant et bien loin du monde du hardware pur et dur.
De plus, s’il ne publiait que quelques articles de temps en temps jusqu’en décembre 2022, le site a commencé à en publier un à deux par jour à partir de janvier 2023, générés par IA, ChatGPT ayant été lancé fin novembre 2022.
VTR-Hardware, Case & Cooling : mort au champ d’honneur
Puisque nous sommes dans les sites en hardware, continuons avec VTR-Hardware lancé par Vincent Valmond en 1999. Le site change de nom pour devenir Revioo en 2007.
Il se met en retrait en 2013 (et passe chez Cooler Master), mais laisse le site entre les mains de Benjamin. Quelques mois plus tard, le média n’est plus mis à jour et ne répond plus après quelques années. VTR-Hardware et Revioo ne répondent plus aujourd’hui.
Profitons pour glisser un petit mot sur Case & Cooling lancé en 2008 par notre confrère Guillaume Henri, mais rapidement arrêté lorsqu’il a pris en charge les relations presse d’ASUS. Il est aussi passé chez Next quelques années avant de continuer chez Les Numériques. Guillaume, si tu nous lis
Clubic à plusieurs vies (y compris sur le hardware)
Dans les plus gros, il y avait bien évidemment Clubic (promis, édito écrit sans aucune contrainte d’Alexandre), dont la partie sur les tests hardware étaient tenus par Julien Jay, qui s’occupe désormais des relations presse chez OVHcloud… mais continue de suivre et de parler de hardware, en témoigne son billet sur Medium à propos de la situation d’Intel.
Après des ballotements, Clubic existe toujours aujourd’hui, mais le hardware n’est plus autant une préoccupation qu’avant, même si des tests sont toujours publiés. Pour la petite histoire, Clubic est né de la fusion entre Démarrez.com et Puissance PC. Ce dernier est revenu d’entre les morts plusieurs fois, mais là encore n’a plus rien à voir avec le site Hardware de l’époque.
Puisqu‘on parle d’anciens sites, certains se souviennent certainement de Presence-PC, devenu Tom’s Hardware en France depuis. Il y a toujours du hardware aujourd’hui, mais on est loin de ce qu’il était avant.
Hardware.fr fermait ses portes il y a 7 ans
Le « goat » de cette époque a également fermé, mais fort heureusement sans connaitre la même zombification que 59 Hardware ou Matbe, pour ne citer que ces deux-là. On parle évidemment de Hardware.fr (lancé sous le nom Achat PC en 1997) avec un duo dès le début des années 2000 : Marc Prieur pour les CPU, Damien Triolet pour les GPU, deux pointures dans leur domaine respectif. Le site a pour rappel été racheté par LDLC dès juin 2000. Il a arrêté ses activités éditoriales en 2018. Le forum, une référence dans le domaine, est toujours actif.
À l’époque, Marc Prieur annonçait que, « dans les prochaines semaines le site de la boutique sera repositionné sur www.hardware.fr, et le site éditorial historique sur old.hardware.fr ». Ce n’est toujours pas le cas, merci ! Les anciens liens continuent ainsi de fonctionner.
Outre-Atlantique, la fermeture d’AnandTech (une référence dans ce domaine) a marqué les esprits. Le site américain a fermé le rideau en aout 2024, après 27 ans d’existence.
Des « fous » se sont lancés en 2023
Mais il existe encore et toujours des irréductibles qui ont envie de parler de hardware. Il y a évidemment Next, dont le hardware est une des composantes principales du site et reste toujours, à titre personnel, un domaine de cœur. Next a pour rappel été lancé sous le nom d’INpact Hardware, avant de devenir PC INpact, Next INpact, de relancer INpact Hardware, de le refermer et devenir simplement Next (cf aussi le petit historique que Jean-Marc a aussi compilé sur notre page « Qui sommes nous ? »).
Il y a également des « fous » qui ont décidé de se lancer dans un « paris osé : lancer un nouveau média Hardware en 2023 », avec Hardware & Co. Il ne s’agit pas d’inconnus, loin de là, puisque l’équipe venait en grande partie de Comptoir du Hardware.
À vous les studios…
Il y a en beaucoup d’autres (coucou Cydoo de Syndrome-OC, JackyPC qui est figé dans le temps), mais trop pour les lister tous… Et vous ? Quels souvenirs gardez-vous de cette époque ? Quels sites, médias et/ou personnes suivez-vous sur le hardware ?
Ne le dites à personne, mais je suis à deux doigts de lancer un site Plextrox dédié aux marques Plextor et Matrox… Oh Wait !
Les infractions liées au numérique sont en hausse cette année, comme les années précédentes. Les services de police et de gendarmeries ont enregistré un peu plus de 348 000 en 2024 et en profitent pour faire le point. On y apprend, sans surprise, que les victimes d’atteintes « numériques » aux personnes sont principalement des femmes.
En guise de préambule, le service statistique ministériel de la sécurité intérieure (SSMSI) rappelle que les infractions liées au numérique sont classées selon quatre grandes catégories : les atteintes aux biens, à la personne, aux institutions, et enfin celles aux législations et réglementations spécifiques au numérique.
Attardons-nous deux minutes sur les définitions. Les atteintes aux biens « désignent toutes les escroqueries, arnaques, détournements de moyens de paiement et infractions occasionnant un préjudice financier, rendues possibles par les outils numériques ».
De leur côté, les atteintes à la personne « désignent essentiellement des atteintes non-physiques comme le harcèlement, les injures, les menaces et les discriminations ». Pour les institutions, cela concerne « les troubles à l’ordre public, les atteintes à la sûreté de l’État et aux institutions », on y retrouve aussi les propos haineux, les obstructions à la justice, le terrorisme, les trafics en tout genre, etc.
Enfin, les infractions liées aux législations et réglementaires « regroupent toutes les infractions au droit d’auteur et spécifiquement à la loi Hadopi, les infractions au RGPD ainsi qu’à la loi pour la confiance dans l’économie numérique et toutes les mesures visant au respect de la vie privée dans le traitement des données ».
Les plaintes sur le numérique sont en hausse depuis des années
Le rapport précise que, pour la première fois, il intègre les données des plaintes de la plateforme Thésée (Traitement harmonisé des enquêtes et des signalements pour les e-escroqueries) qui, comme son nom l’indique, permet de signaler des escroqueries en ligne.
Quoi qu’il en soit, les services de sécurité ont enregistré, selon le rapport, un peu plus de 348 000 infractions « numériques » en 2024, soit une hausse de 2 % par rapport à 2023. L’année dernière, l’augmentation était de 13 % ; elle était même de 17 à 20 % en 2019, 2020 et 2021.
Atteintes aux biens et aux personnes représentent 95 % des plaintes
Les atteintes aux biens représentent 65 % (226 300), tandis que celles aux personnes sont aux alentours de 30 % (103 300). Les institutions sont à 5 % (17 000 plaintes). Il ne reste donc que quelques miettes pour celles liées aux législations et réglementations spécifiques au numérique à moins de 1 % (1 500 plaintes).
Depuis 2016, le nombre d’infractions est en forte progression pour les quatre catégories, avec 9 à 15 % de plus en moyenne par an, comme en attestent les graphiques ci-dessous :
Les plaintes liées aux biens reculent (un peu), les autres progressent
Mais dans le détail, les tendances ne sont pas aussi homogènes. Les atteintes aux biens reculent de 1 % par rapport à l’année 2023, avec 226 300 crimes et délits enregistré par la police et la gendarmerie nationales, dont 50 800 via Thésée.
Les trois autres catégories sont en hausse :+ 7 % pour les atteintes aux personnes,+ 7 % également pour les institutions et enfin + 10 % pour celles liées aux législations et réglementations spécifiques au numérique.
Les victimes sont majoritairement des femmes majeures
Dans tous les cas, la grande majorité des victimes sont majeures. Par contre, et cela ne devrait malheureusement pas surprendre grand monde : « les profils des personnes majeures victimes d’atteintes « numériques » aux personnes sont majoritairement des femmes (66 %), et âgées de moins de 45 ans ».
« Les femmes de 18 à 44 ans représentent 49 % des victimes ce type d’atteintes « numériques » alors qu’elles ne représentent que 21 % de la population française majeure et qu’aucune différence notable n’est constatée en matière de taux d’équipement en internet selon le sexe », note le rapport.
À contrario, sur les atteintes numériques aux biens, les femmes représentent « un peu moins d’une [personne] sur deux », et 61 % des victimes mineures d’atteintes « numériques » aux biens sont des garçons, dont les deux tiers ont plus de 15 ans.
De l’autre côté de la barrière, 60 000 personnes ont été mises en cause (MEC) en 2024, dont 51 100 majeurs : 8 200 pour des atteintes aux biens (+ 3 %), 31 900 pour des atteintes aux personnes (+ 4 %). Sur l’année 2024, 8 900 mineurs ont également été mis en cause : plus de 2 sur 3 pour des atteintes aux personnes et 1 sur 4 pour des atteintes aux biens.
Les filles mineures sont 2,5 fois plus attaquées que les garçons
L’an passé, le SSMSI avait déjà documenté que les atteintes numériques à la personne (harcèlement, injures, menaces et discriminations) « visent pour leur part majoritairement les femmes, qui représentent 67 % du total des plaintes déposées », et que les filles mineures sont 2,5 fois plus attaquées que les garçons :
« Les femmes âgées de 18 à 44 ans ont représenté 50 % des victimes d’une atteinte numérique à la personne en 2023, alors que cette catégorie ne constituait que 16 % de la population française au 1er janvier 2024 ».
A contrario, 62 % des personnes mises en cause pour des atteintes aux biens en 2023 étaient des hommes majeurs de moins de 45 ans, alors qu’ils ne représentent, eux aussi, que 16 % de la population française.
Voici le résumé de ce que pourraient proposer ces cartes graphiques :
RTX 5060 Ti : 4 608 Cuda Cores, 8 ou 16 Go de GDDR7 sur 128 bits et TDP de 180 watts
RTX 5060 : 3 840 Cuda Cores, 8 Go de GDDR7 sur 128 bits et TDP de 150 watts
RTX 5050 : 2 560 Cuda Cores, 8 Go de GDDR6 sur 128 bits et TDP de 120 watts
La RTX 5060 Ti serait donc proposée avec 8 ou 16 Go de mémoire vive (GDDR 7), contre 8 Go uniquement pour les deux autres. Plus on descend en gamme, plus le nombre de Cuda Cores baisse, comme toujours. La RTX 5050 enfin se contenterait de GDDR6. À confirmer bien évidemment, et aussi à compléter.
Pour rappel, voici les caractéristiques des RTX 4060 et 4060 Ti :
Reste maintenant à connaitre les prix, car ce seront eux qui permettront de voir si les cartes sont intéressantes par rapport aux autres de la série 50 et surtout comparés à celles des générations précédentes.
La Commission européenne a mené ce qu’elle appelle une opération « coup de balai », une expression pour parler d’une opération conjointe avec les autorités nationales chargées de faire appliquer la législation.
La dernière enquête concerne les « professionnels spécialisés dans la vente de biens d’occasion, tels que les vêtements, les équipements électroniques ou les jouets ». Le résultat est sans appel : ils ont contrôlé « 356 revendeurs en ligne et relevé de potentielles infractions à cette législation pour 185 (52 %) d’entre eux ».
Les griefs sont multiples :
« 40 % n’ont pas informé clairement les consommateurs de leur droit de rétractation, comme le droit de retourner le produit dans un délai de 14 jours sans justification ni frais;
45 % n’ont pas correctement informé les consommateurs de leur droit de renvoyer des biens défectueux ou des biens dont l’aspect ou le fonctionnement ne répond pas aux spécificités énoncées dans la publicité ;
57 % n’ont pas respecté la période de garantie légale d’au minimum un an prévue par la loi pour les biens d’occasion ;
sur les 34 % de professionnels qui ont mis en avant des allégations environnementales sur leur site web, 20 % ne les avaient pas suffisamment étayées et 28 % avaient présenté des allégations manifestement fausses, trompeuses ou susceptibles de constituer des pratiques commerciales déloyales ;
5 % n’ont pas correctement communiqué leur identité, et 8 % n’ont pas indiqué le prix total du produit, toutes taxes comprises »
Désormais, la balle est dans le camp des autorités de protection des consommateurs qui « vont à présent décider s’il y a lieu de prendre des mesures contre les 185 professionnels qui seront soumis à une enquête plus approfondie ».
« Lorsque vous achetez un produit ou un service numérique, il doit être conforme à l’usage attendu et à la description faite par le vendeur. En cas de défaut existant au moment de la délivrance du bien ou du service, vous pouvez mettre en œuvre la garantie légale de conformité. Le défaut doit vous apparaître dans un délai de deux ans à compter de la délivrance du bien, qu’il soit neuf, d’occasion, reconditionné, ou qu’il s’agisse d’un service numérique », rappelle le site officiel de l’administration française.
Sur cette page enfin, il est précisé que, concernant la vente à distance (et le démarchage téléphonique), « le droit de rétractation s’applique aussi si le produit est soldé, d’occasion ou déstocké ». Le délai légal minimum est de 14 jours.
Une précision : « Le décompte du délai de 14 jours commence le lendemain de la conclusion du contrat ou de la livraison du bien. Si ce délai expire un samedi, un dimanche ou un jour férié, il est prolongé jusqu’au premier jour ouvrable suivant ».
AMD vient de confirmer la date de sortie de deux Ryzen 9 X3D, avec des cœurs Zen 5 et du 3D V-cache (64 Mo supplémentaire sur le L3) de seconde génération. Ils avaient été annoncés au début de l’année lors du CES de Las Vegas et viennent accompagner le Ryzen 7 9800X3D, que l’on trouve à partir de 542 euros (524 euros en version « tray », comme l’indique ViveLesTouristes dans les commentaires).
La principale différence vient du fait que les cœurs CPU Zen 5 sont placés au-dessus du 3D V-Cache, alors que c’était l’inverse sur la première génération. Ils sont ainsi « plus près de la solution de refroidissement, offrant des vitesses d’horloge plus élevées à des températures plus basses, et donc avec de meilleures performances par rapport à la génération précédente », affirme AMD.
Le Ryzen 9 9900X3D dispose pour rappel de 12C/24T avec un total de 128 Mo de mémoire cache L3 (960 ko L1 et 12 Mo L2). Son grand frère, le Ryzen 9 9950X3D, pousse à 16C/32T et 128 Mo de cache L3 également. Avec son nombre de cœurs plus important, il a 16 Mo de cache L2, soit un total de 144 Mo contre 140 Mo pour le 9900X3D.
Les deux processeurs seront disponibles à partir du 12 chez les revendeurs, pour respectivement 599 et 699 dollars. Le prix en euros n’est pas précisé… en espérant qu’AMD ne refasse pas le même coup qu’avec les Radeon RX 9070 XT.
Des priorités prioritaires depuis déjà des années…
Pour les trois années à venir, la DGCCRF veut se renforcer autour de quatre grands axes. On y retrouve évidemment des incontournables comme les questions de consommation durable, mais aussi des sujets d’actualités avec les jeunes et les influenceurs. Deux dossiers de fonds qui « trainent » depuis des années et qui concerne quotidiennement les consommateurs sont aussi mis en avant : les dark patterns et le démarchage téléphonique.
Une présentation avant d’entrer dans le vif du sujet. La Direction générale de la concurrence, de la consommation et de la répression des fraudes (DGCCRF pour les intimes), est une administration du ministère de l’Économie, elle n’est donc pas indépendante, contrairement à d’autres comme l’Arcom, l’Arcep, la CADA, etc.
Préparer l’avenir, avec des actions concrètes
En une phrase, sa mission est d’« enquêter pour protéger les consommateurs et les entreprises ». La protection des consommateurs passe aussi bien par la sécurité (produits non alimentaires) que les intérêts économiques. La DGCCRF doit aussi « veiller au bon fonctionnement concurrentiel des marchés » et « lutter contre les fraudes économiques ».
Elle vient de dévoiler un nouveau plan stratégique pour les années 2025 à 2028. « Plus qu’une feuille de route, ce nouveau plan stratégique porte une vision coconstruite avec les équipes et parties prenantes, qui fixe un cap ambitieux, dans un contexte marqué par des attentes sociétales de plus en plus exigeantes », explique la DGCCRF dans son discours introductif. Son plan doit lui permettre de « préparer l’avenir, avec des actions concrètes ».
La DGCCRF veut « maximiser l’impact » de ses actions
Pour les trois années à venir, quatre grands axes stratégiques sont mis en avant. Le premier doit « maximiser l’impact » de ses actions. Cela passera notamment par une meilleure exploitation des données remontées via la plateforme Signalconso qui permet aux consommateurs de signaler un problème avec une entreprise.
Autre point : « Enrichir nos pratiques d’enquête et de contrôle et renforcer les suites ». La répression des fraudes ne veut pas simplement taper du poing sur la table, elle veut visiblement rester dissuasive afin de « faire cesser rapidement les pratiques les plus dommageables ».
Sur le volet répressif, la DGCCRF veut ainsi « mobiliser davantage la réquisition numérique, développer les sanctions administratives pour certains manquements et de réprimer plus fortement les fraudes les plus préjudiciables pour l’économie ».
Consommation durable et information environnementale
On passe maintenant au deuxième axe : « Accompagner les transformations de l’économie et de la société ». La « consommation durable, désirable et équitable ». La DGCCRF veut développer son expertise et ses capacités d’enquêtes. Elle souhaite également encourager l’écoconception, tout en « veillant à la loyauté de l’information environnementale ».
Cette semaine pour rappel, 33 revendeurs se sont engagés autour d’une charte pour réduire l’impact environnemental de l’e-commerce, avec la Fevad. Les grands noms du moment l’ont signés, mais il y a quelques absents notables comme le groupe LDLC et les chinois tels qu’Alibaba, Temu et Shein pour ne citer qu’eux.
La Direction générale entend aussi s’intéresser aux nouvelles pratiques, rappelant que les consommateurs ont des pratiques diverses : « les jeunes par exemple tiennent davantage compte des avis des influenceurs pour acheter un produit ou un service ».
La DGCCRF dispose pour rappel depuis début 2023 d’un nouvel outil : le « name and shame » sur les injonctions, et pas seulement sur les sanctions administratives. Elle s’en est servie à plusieurs reprises (ici et là par exemple).
En 2024, elle publiait un triste bilan : sur 310 influenceurs contrôlés, la répression des fraudes avait délivré pas moins de 151 avertissements, injonctions et suites pénales. Le bilan 2023 n’était pas des plus glorieux non plus.
Dans un autre registre, la DGCCRF entend « prendre en compte les spécificités des territoires ultras marins en mettant en place un plan annuel spécifique, visant à mieux protéger les consommateurs et notamment les plus vulnérables ».
« Viser la même protection sur internet qu’en magasin »
Autre gros morceau de ce deuxième axe : l’ecommerce. la DGCCRF commence par un état des lieux : « plus de la moitié des signalements des consommateurs sur notre plateforme dédiée, signal.conso.gouv.fr, concerne des achats sur internet ». Il faut dire que les achats sur Internet ont le vent en poupe : « Au cours des douze derniers mois, ce sont 70,1 % des Français de plus de quinze ans qui ont effectué un achat sur internet », précise la Direction générale des entreprises.
La répression des fraudes rappelle que plusieurs textes européens ont été adoptés ces dernières années (DSA, DMA, RSGP, RIA…), mais aussi que « le numérique ne cesse jamais d’évoluer et d’innover » et qu’il faut donc constamment s’adapter et « proposer de nouveaux leviers d’action si nécessaire ».
La répression des fraudes veut « promouvoir un e-commerce de confiance » en renforçant par exemple les campagnes de prévention des arnaques et en valorisant les pratiques vertueuses.
Détection automatique des dark patterns
Rémi Stefanini, délégué à la transition numérique à la DGCCRF, apporte des précisions : « Nous renforcerons la lutte contre les dark patterns, ces interfaces web manipulatoires, en organisant une revue systématique des principales plateformes ». Avec le Pôle d’Expertise de la Régulation Numérique (PEReN), la DGCCRF va essayer de développer « un outil de détection automatique ».
Cela ne surprendra pas grand monde, mais une étude des CNIL a monté que les dark patterns étaient partout sur Internet. C’était la conclusion d’une enquête du GPEN, réseau d’organismes agissant pour la protection de la vie privée au sein de pays membres de l’OCDE, suite au « ratissage » de plus de 1 000 sites et applications mobiles.
Dark patterns : un « un sujet prioritaire » depuis… 2023
Dans un rapport de juin 2023, le ministère de la transformation expliquait qu’une étude de la Commission Européenne avait « identifié des dark patterns sur 97 % des 75 sites les plus populaires dans l’UE ». Déjà à l’époque (il y a près de deux ans), il était précisé que « l’identification et l’instruction de ces dark patterns [étaient] devenues un sujet prioritaire pour les autorités de protection des consommateurs, en France et dans le monde ». Espérons que le plan stratégique se donne vraiment les moyens d’agir.
C’était l’occasion de rappeler que les dark patterns ne concernent pas que le design des formulaires d’acceptations qui poussent à des actions forcées. Le mécanisme de conception trompeur le plus utilisé est l’« utilisation d’un langage complexe et déroutant dans les politiques sur la vie privée ».
La DGCCRF donne quelques exemples de dark patterns courants sur les sites de vente en ligne : « Compte à rebours ou messages d’urgence, demandes multiples de confirmations de vos choix, choix présélectionnés, abonnement caché, entrave au désabonnement, panier rempli à votre insu ». En juin dernier, l’UFC-Que Choisir montait au créneau contre les dark patterns des sites d’e-commerce.
Renforcer la lutte contre le démarchage téléphonique
Le délégué affirme aussi que la répression des fraudes va renforcer sa « lutte contre le démarchage téléphonique, en automatisant par exemple la détection des numéros de téléphone les plus signalés afin de faciliter les enquêtes ». Nous avons déjà publié plusieurs guides sur le sujet :
Le troisième axe pour les années 2025 à 2028 est de « mener une stratégie d’ouverture et de coopération forte ». Il s’agit pour la DGCCRF de « peser aux niveaux européen et international », de renforcer les partenariats institutionnels et de « renforcer la confiance des consommateurs et des entreprises ».
Le quatrième et dernier axe vise à renforcer la dynamique de réseau et les compétences de la DGCCRF. Elle veut ainsi attirer de nouveaux talents et « tirer pleinement parti du numérique » pour mener ses actions.
Hier, c’était le grand jour pour les nouvelles Radeon RX 9070 et 9070 XT d’AMD, les premières exploitant l’architecture RDNA 4. Les cartes sont en vente et les tests des confrères publiés. Nous avons décidé de faire un petit tour d’horizon à J+1.
Conversion dollars vers euros : AMD moins gourmand que NVIDIA
Les nouvelles Radeon RX 9070 et 9070 XT étaient annoncées à 549 et 599 dollars, sans précisions sur le prix en France. On peut maintenant voir que les tarifs sont de 629 et 689 euros dans nos contrées, du moins en théorie.
Par rapport au prix en dollars, le tarif de base en euros prend donc environ 15 % (cela correspond aux taxes, aux frais de conversion…). Chez NVIDIA, la hausse du passage du dollar à l’euro sur les RTX 5070 et 5070 Ti était plus importante avec 18 % environ. Les cartes étaient annoncées à 549 et 749 dollars, pour 649 et 884 euros.
Rapide détour par les tests (sans grande surprise)
Commençons par quelques tests. Pour Hardware & Co, « l’intérêt de la RX 9070 XT réside essentiellement dans sa tarification ». Elle se place sous la RTX 5070 Ti en performances, mais garde l’avantage du rapport performances/prix selon nos confrères. « La dernière née des rouges pose également souci à la RTX 5070 qui pour le coup est positionnée beaucoup trop proche », ajoutent-ils. Quant à la RX 9070, elle se place devant la RTX 5070 en rastérisation, mais derrière en ray tracing.
Autres tests chez Les Numériques. La Radeon RX 9070 se place entre les GeForce RTX 5070 et 5070 Ti en 1440p, tandis que la RX 9070 XT est au coude à coude avec la RTX 5070 Ti et la RTX 4080 Super. « Le passage à la définition 4K permet de creuser les écarts, mais aussi d’apprécier la quantité de mémoire disponible. À ce petit jeu, la Radeon RX 9070 s’en sort avec les honneurs », explique notre confrère.
630 euros pour une Radeon RX 9070 : la réalité est bien différente
Bon, qu’en est-il des prix ? Chez LDLC, la RX 9070 débute à 630 euros et 690 euros pour la version XT, mais les produits sont en rupture de stock. La carte la moins chère en stock est la RX 9070 de Sapphire Pulse à 800 euros, soit 170 euros de plus que le tarif de base. Certaines Radeon RX 9070 XT frôlent même les 1 000 euros, soit 300 euros de plus que le tarif « recommandé ».
La situation est plus ou moins la même chez Top Achat et Materiel.net qui font partie du même groupe que LDLC. Notons tout de même une Radeon RX 9070 OC ASUS TUF à… 930 euros (c’est bien la version classique, pas la XT).
Passons chez Cybertek, avec les mêmes prix de base (630 et 690 euros) et les mêmes stocks inexistants. Le revendeur n’a qu’une seule carte en stock pour le moment : la RX 9070 Sapphire Nitro+ OC de Sapphire à 750 euros, c’est toujours 50 euros de moins que LDLC. Même chose chez Grosbill, qui appartient pour rappel à Cybertek.
Une RX 9070 XT à 900 euros, 1 150 euros pour une 9070 XT
Chez Cdiscount, la RX 9070 Pulse s’affiche à… 900 euros et on passe à 940 euros pour une version Pure OC. Le revendeur dépasse allègrement les 1 000 euros avec la version XT : 1035 euros pour la Pure OC et jusqu’à 1 150 euros pour la Nitro+ OC en Radeon RX 9070 XT.
Nous faisons également un tour chez un autre revendeur « officiel » d’AMD : Infomaxparis. Ça va vite : aucune carte n’est en stock. Détail surprenant, la carte la moins chère est une Radeon RX 9070 XT à 690 euros, puis il faut passer à 720 euros pour une Radeon 9070.
Stock : circulez, il n’y a (presque) rien à voir
Nous en profitons pour regarder la situation chez NVIDIA, avec des stocks également très limité sur les GeForce RTX 5070, comme on peut le voir chez LDLC (aucune GeForce en stock). Chez Cybertek, c’est encore pire. Si on prend l’ensemble des Radeon RX 9070, 9070 XT, GeForce RTX 5070 et 5070 Ti, on arrive à… une seule carte en stock.
C’est fait. Ariane 6 a réussi son premier lancement commercial. La mission est un succès sur toute la ligne, avec une dépose précise du satellite militaire CSO-3 à 800 km d’altitude (orbite héliosynchrone), après plusieurs réallumages (prévus) du moteur Vulcain.
Cette fois, c’était (enfin) la bonne
Après de multiples reports, dont un dernier en début de semaine, Ariane 6 a finalement décollé en fin d’après midi de Guyane. L’Europe peut pousser un ouf de soulagement : la mission est un succès sur toute la ligne.
Le décollage s’est effectué sans la moindre anicroche puis, après une heure de vol, a bien effectué le largage de la charge utile. Entre temps, le moteur Vinci a été redémarré plusieurs fois pour ajuster la trajectoire de l’étage supérieur, comme prévu.
Les premières minutes de fonctionnement sont juste idéales et parfaites
Vers 18h30, Arianespace indiquait que « le satellite CS0-03 vient d’être déposé précisément à son point de livraison afin qu’il puisse à son tour remplir brillamment sa mission en symbiose avec CSO-01 et CSO-02 ».
« On a acquis le signal de télémétrie du satellite, on a détecté sa bonne séparation. La séquence automatique a démarré, on a déployé les quatre panneaux solaires […] On peut dire que les premières minutes de fonctionnement sont juste idéales et parfaites », ajoute Paul Arberet, chef de projet senior au CNES.
Souveraineté, souveraineté et souveraineté
« Le retour de Donald Trump à la Maison-Blanche avec Elon Musk à ses côtés a déjà des conséquences considérables sur nos partenariats sur la recherche, sur nos partenariats commerciaux », a déclaré Philippe Baptiste dans le live accompagnant le lancement (l’intégralité du live figure dans la vidéo plus bas dans cet article) : « Dois-je mentionner les incertitudes qui pèsent aujourd’hui sur nos coopérations avec la NASA et la NOAA, quand des programmes aussi emblématiques que l’ISS sont remis en cause unilatéralement par Elon Musk ? »
L’ancien président du CNES et désormais ministre chargé de l’Enseignement supérieur et de la recherche, rattaché à Élisabeth Borne, a sonné la charge contre les États-Unis et les enjeux de souveraineté :
« Si nous voulons conserver notre indépendance, assurer notre sécurité, préserver notre souveraineté, nous devons nous donner les moyens de notre autonomie stratégique. Et le spatial en est une composante incontournable. L’espace est présent partout, de nos téléphones aux champs de bataille, dans les télécommunications, la navigation et l’observation de la Terre. Ce lancement joue un rôle particulier car il permet la mise en orbite d’une nouvelle capacité spatiale militaire […] Nous ne devons pas céder à la tentation de préférer SpaceX ou un autre concurrent qui paraît plus à la mode, plus fiable ou moins cher aujourd’hui ».
Pour Philippe Baptiste, Ariane 6 est un « nouveau jalon essentiel » de notre souveraineté. Cette question n’est pas nouvelle, elle occupe même l’espace médiatique depuis quelques années (et encore ici), mais elle est devenue d’autant plus importante avec le retard d’Ariane 6 et la mise à la retraite d’Ariane 5, sans compter les déboires de Vega(-C).
« Une étape importante du retour à l’autonomie et à la souveraineté spatiale française et européenne est franchie », a de son côté déclaré Sébastien Lecornu, ministre des Armées. Il ajoute que CSO permet « à nos armées, et à nos alliés, d’obtenir des images optiques et infrarouges à une définition inégalée en Europe ».
Vous pouvez revoir le lancement et les discours sur la vidéo ci-dessous :
Après les Box 5G, la 5G StandAlone (5G SA ou 5G+) débarque dans un premier forfait de téléphonie mobile, dans la gamme « pro ». Les avantages sont nombreux pour Orange et proviennent en grande partie des fonctionnalités de la 5G SA. Explications.
Màj du 6 mars 2025 : Après le lancement pour les professionnels, « Orange élargit l’accès à la 5G+ sur le marché grand public », avec des offres disponibles dès aujourd’hui. Il s’agit d’un format Série Spéciale 180 Go 5G+ à 41 euros par mois, sans engagement. Il permet de profiter d’une « d’une bande passante dédiée aux clients de l’offre 180 Go 5G+ ».
Orange annonce aussi que ses clients grand public 5G avec un smartphone compatible peuvent « profiter gratuitement de l’option 5G+ », le nom commercial d’Orange pour parler de la 5G SA (StandAlone, sur la bande des 3,5 GHz chez l’opérateur) ne se basant pas sur un cœur de réseau 4G.
Actualité originale du 6 février : Dans un communiqué de presse, Orange annonce « une offre inédite 5G + avec une bande passante dédiée pour ses clients professionnels ». Qu’est-ce que cela veut dire au-delà du discours bien rodé des équipes marketing ?
Nous avons déjà expliqué ce qu’est la 5G+ d’Orange : c’est le nom commercial de la 5G StandAlone (ou 5G SA). Pour rappel, la 5G utilisait à son lancement et durant ces dernières années un cœur de réseau 4G pour fonctionner, d’où son appellation technique de 5G Non StandAlone.
Orange remet donc le couvert aujourd’hui avec son forfait Performance série spéciale 5G+. Passons rapidement sur ses caractéristiques qui n’ont rien de particulier : 350 Go de data, appels et SMS/MMS illimités pour 79 euros HT par mois, sans engagement.
Orange reprend les poncifs habituels de la 5G : hausse des débits et baisse de la latence. Mais la 5G+ apporte aussi des nouveautés intéressantes, notamment la technologie VoNR (Voice over New Radio). Ainsi, la « connexion data est maintenue en 5G lors d’un appel voix ». Avant, la data repassait en 4G lors d’un appel avec VoLTE et en 3G dans le cas contraire.
Orange met aussi en avant « une sécurisation accrue des données sensibles grâce au chiffrement natif des identifiants IMSI et à l’authentification renforcée des utilisateurs sur le réseau ». Nous avons voulu télécharger la fiche tarifaire et la description du service indiqués sur cette page afin d’avoir de plus amples informations, mais les liens sont cassés.
Orange met en avant des débits de 1,5 Gb/s… inférieurs à ceux de la 5G
Comme chez Free, la 5G SA est uniquement disponible sur la bande des 3,5 GHz, dont le « déploiement [est] en cours ». Le débit maximum annoncé par Orange est de 1,5 Gb/s en téléchargement avec l’agrégation de la bande des 700 Mhz en 4G, et de 200 Mb/s en émission.
Selon le propre site d’Orange, la 5G+ fait donc moins bien que la 5G en débit théorique. En effet, en 5G le débit maximum théorique en réception est de 2,1 Gbit/s selon Orange. En émission, c’est la même chose avec 200 Mb/s dans les deux cas.
Cette quoi cette « bande passante dédiée » ? Du slicing…
Orange revient à plusieurs reprises sur la notion de bande « prioritaire » : « Au travers d’une bande passante dédiée Premium, le client bénéficie d’une qualité de service différenciée sur le réseau mobile Orange. Ainsi, même en cas de forte utilisation du réseau mobile, ses débits sont préservés ».
« Lors des évènements : Pour les services de billetterie ou les solutions de paiement, la bande passante dédiée permet une connexion stable et assure la fluidité des opérations », ajoute l’opérateur en guise d’exemple.
Là encore, il s’agit d’une dénomination commerciale d’une technologie bien connue de la 5G : le network-slicing. Elle permet de découper le réseau en « en plusieurs sous-réseaux, que l’on appelle des tranches, ou “slices” en anglais », explique Orange.
Les usagers sur une tranche sont d’une certaine manière isolés de ceux d’une autre tranche. Les clients d’un forfait 5G+ peuvent ainsi profiter d’une tranche rien que pour eux en 5G SA, tandis que les autres se partagent une autre tranche. Une surcharge sur la seconde tranche ne devrait pas avoir d’impact sur la première.
Sur cette page dédiée au network-slicing, Orange rappelle que « tout ceci était déjà possible avec la 4G d’un point de vue technique », mais la 5G apporte « une vraie valeur ajoutée » grâce « à une architecture réseau virtualisée ». SFR d’ailleurs, proposait pendant un temps des forfaits 4G avec « internet mobile prioritaire ». Ils permettaient, « en cas d’affluence » d’avoir un « débit généralement plus rapide que celui des utilisateurs du réseau SFR non détenteurs du service ». C’était il y a maintenant 10 ans, en 2015.
Orange ne précise pas quand de nouveaux forfaits 5G+ seront disponibles ni si cette technologie sera proposé au grand public dans un proche avenir.
Après l’annonce des nouveaux iPad (Air), Apple enchaine comme prévu avec un nouveau MacBook Air. Principale nouveauté : le passage au dernier SoC maison, le M4. Si toutes les variantes ont 10 cœurs CPU (4P + 6E), le MacBook Air 13 d’entrée de gamme (1 199 euros, soit 100 euros de moins que l’entrée de gamme précédente) n’a que huit cœurs GPU, contre dix pour les autres.
Suivant les configurations, il est possible d’avoir jusqu’à 32 Go de mémoire unifiée, contre 24 Go pour la génération précédente en M3. On retrouve une nouvelle « Caméra 12MP Center Stage avec prise en charge de Desk View », aussi bien sur les versions 13 et 15 pouces. Pour le reste, pas de changement, si ce n’est une batterie de 53,8 Wh au lieu de 52,6 Wh sur le 13 pouces. Pas de changement en 15 pouces avec 66,5 Wh. Signalons que le passage à la puce M4 permet de brancher deux écrans externes, au lieu d’un seul précédemment.
Un nouveau coloris bleu ciel est proposé. On passera sur les nombreux superlatifs d’Apple autour de cette nouvelle « magnifique » couleur. Les précommandes sont ouvertes, la disponibilité est prévue pour le 12 mars. Vous pouvez comparer les différentes versions du MacBook Air par ici pour le 13 pouces et par là pour le 15 pouces.
Mac Studio M4 Max ou M3 Ultra suivant les besoins… et la bourse
Apple annonce aussi un nouveau Mac Studio avec au choix une puce M4 Max ou une nouvelle M3 Ultra (nous y reviendrons dans un article dédié). La machine passe à Thunderbolt 5 (quatre ports sur le M4 Max, six sur le M3 Ultra), avec du 10 GbE. L’ordinateur propose jusqu’à 512 Go de mémoire unifiée (contre 192 Go pour la version M2 Ultra) et 16 To de SSD. Là encore, un comparatif est disponible.
Voici comment Apple positionne les deux versions de sa machine :
« Le nouveau Mac Studio avec M4 Max est le choix idéal pour les monteurs vidéos, les étalonneurs, les développeurs, les ingénieurs, les photographes, les professionnels créatifs et, de manière générale, tous les utilisateurs ayant besoin d’une machine capable de les suivre dans les workflows les plus intenses […]
Le Mac Studio avec M3 Ultra gère les tâches les plus exigeantes avec une facilité déconcertante. Tirant parti des nombreux cœurs intégrés à son CPU et son GPU ainsi que de ses quantités colossales de mémoire unifiée, il délivre des performances près de deux fois supérieures à celles du Mac Studio avec M4 Max pour les tâches les plus exigeantes ».
Comptez 2 499 euros pour le Mac Studio M4 (14 cœurs CPU et 32 cœurs GPU) et 4 999 euros pour la version M3 Ultra (28 cœurs CPU, 60 cœurs GPU). Les machines seront aussi disponibles à partir du 12 mars également.
À peine une demi-heure avant son premier lancement commercial, Arianespace annulait le lancement à cause de problème sur un « équipement sol en interface avec le lanceur ». La résolution du problème a été rapide puisqu’une nouvelle date est déjà programmée : demain.
« Ariane 6 et son passager, le satellite CSO-3, sont dans des conditions stabilisées et en sécurité », affirme Arianespace. CSO-3 est pour rappel le troisième satellite du programme MUSIS (Multinational Space-based Imaging System) dédié à l’observation de la Terre au service de la défense. « Les satellites CSO-1 et CSO-2 avaient été lancés respectivement en 2018 et 2020 », rappelle le CNES.
CSO-3 sera largué si tout va bien sur une orbite héliosynchrone à 800 km d’altitude. « Son injection interviendra 1 heure et 6 minutes après le décollage », explique ArianeSpace.
En juillet 2024, avec des années de retard sur le planning initial, Ariane 6 décollait sans encombre et réalisait sa mission principale. Avec la mission secondaire, c’était une autre histoire à cause d’un groupe auxiliaire de puissance (GAP, ou APU pour Auxiliary Power Unit) capricieux.
Il faut maintenant transformer l’essai avec un vol commercial. Le premier devait avoir lieu fin 2024, mais il a été repoussé plusieurs fois pour arriver à ce jeudi 6 mars. La fenêtre de lancement s’ouvre à 17h24.
Le CNES proposera en direct une émission (à partir de 16h55) pour suivre ce lancement. Il s’agit en effet de conserver une autonomie d’accès à l’espace, un enjeu d’autant plus important dans le contexte géopolitique actuel.
Quand on pense qu'il suffirait de ne pas les acheter pour que ça ne se vende plus
33 entreprises, parmi lesquelles des géants en France, ont signé la charte lancée par le gouvernement et portée par la Fédération du e-commerce. Elle comprend 11 engagements sur les différentes étapes d’après achat : entrepôts, emballages, livraisons et éventuels retours.
Cela fait des années que les autorités françaises travaillent autour de « chartes » pour les acteurs du e-commerce. Il y a maintenant six ans, nous avons eu celle pour « garantir des relations loyales et transparentes entre les plateformes de e-commerce et les TPE et PME françaises », puis un « label » en 2020 pour reconnaitre « la prise d’engagements ambitieux de la part des plateformes ».
En 2021, une première « Charte d’engagements pour la réduction de l’impact environnemental du commerce en ligne » a été mise en place avec des acteurs volontaires du e-commerce. Quinze enseignes l’avaient à l’époque signée : Cdiscount, Ebay, FNAC DARTY, La Redoute, lentillesmoinscheres, Maison du Monde, Millet Mountain Group, OTELO, Rakuten, Groupe Rosa, Sarenza, Showroomprive, SOS ACCESSOIRE, Veepee. Amazon et le groupe LDLC brillaient alors par leur absence.
33 signataires, mais encore beaucoup d’absents de poids
Cette charte a été actualisée et renforcée en 2024, avec plus du double de signataires et l’arrivée du géant Amazon. En effet, en ce début du mois de mars, elle est signée par 33 entreprises.
Voici la liste : Agrizone, Amazon, AUTF, Blancheporte, Boulanger, Carrefour, Cdiscount, Colissimo, E.Leclerc, Ebay, Electro depot, Fleurance nature, FM Logistic, Fnac Darty, Françoise Saget, ITinSelL Software, Label emmaüs, Laredoute, Lentillesmoinscheres.com, Leroy Merlin, Maison du monde, Manutan, Mondial Relay, Quelbonplan, Rakuten, Groupe Rosa Linvosges, Showroom privé, SOS accessoire, Tikamoon, Topaz, Veepee, Wooday et Zalando.
Par rapport à la première version de 2021, quelques enseignes ne sont plus présentes : Millet Mountain Group, OTELO et Sarenza. On note encore l’absence du groupe LDLC (Rue du Commerce, Top Achat, Hardware.fr…) dans les signataires. L’entreprise est pour rappel dans une phase difficile financièrement et prévoit le licenciement de 88 personnes pour « motif économique ».
Il en est de même pour Leboncoin, Vinted ainsi que pour des mastodontes chinois comme Aliexpress, Temu et Shein. Philippe Wahl, PDG de la Poste, expliquait récemment qu’Amazon, Temu et Shein représentait à eux trois 43 % des colis de La Poste en Europe, dont 22 % pour Temu et Shein (contre moins de 5 % il y a cinq ans).
Amazon explique d’ailleurs que cette charte s’inscrit dans sa volonté de « réduire son empreinte environnementale et atteindre zéro émission nette de CO₂ d’ici 2040 ». La FEVAD (Fédération du e-commerce et de la vente à distance) est aussi partie prenante et veillera à la valorisation des engagements.
L’e-commerce a le vent en poupe selon la Direction générale des entreprises : « Au cours des douze derniers mois, ce sont 70,1 % des Français de plus de quinze ans qui ont effectué un achat sur internet, soit une augmentation de 500 000 personnes en un an. En 2023, 1,7 milliard de colis ont été traités en France, ce qui représenterait 1,7 million de tonnes de CO2 émis, selon l’ADEME ».
Il y a deux semaines, la FEVAD publiait son bilan 2024 du e-commerce qui, sans surprise, se porte bien : « le e-commerce français confirme son dynamisme et atteint un chiffre d’affaires record de 175,3 milliards d’euros, en hausse de 9,6% par rapport à l’année précédente ».
La vente de produits progresse de 6 % à 66,9 milliards d’euros, un niveau équivalent à celui de 2021. « Un achat en ligne par semaine en moyenne par cyberacheteur, pour un total annuel de 4 216 euros dépensés en ligne », selon la fédération.
La liste des onze engagements
Cette charte édition 2025 comprend 11 engagements répartis autour de cinq grands axes : l’information du consommateur, les retours, les emballages, les entrepôts et livraisons, et enfin le suivi des engagements. Les signataires de la charte devront rendre compte chaque année aux services de l’État compétents.
Mettre en avant une offre significative de produits :
fabriqués en France ou en Europe, bénéficiant de labels environnementaux, de seconde main…
Favoriser les bons gestes de commande entre les catégories et au sein d’une même catégorie.
Informer le consommateur des leviers pour diminuer l’impact environnemental de la livraison :
indiquer les modalités, ainsi que les modes alternatifs et décarbonés pour retirer son colis,
proposer plusieurs délais de livraison et indiquer leurs impacts,
indiquer aux consommateurs si leurs colis peuvent être livrés par voie aérienne,
en option : afficher une valeur d’impact (en g ou kgCO₂ équivalent pour le colis ou par colis) et/ou une information sur l’impact environnemental de la livraison.
Se doter d’une politique interne sur les retours avec des objectifs :
prévention des demandes de retours, mais rappelons que cela demeure un droit pour le consommateur depuis la loi Hamon,
gestion des produits non désirés, effectivement retournés ou non,
communication publicitaire responsable.
Mettre en place au moins 3 actions directes de prévention des demandes de retours :
outils internes pour caractériser les raisons du retour,
suivi, accompagnement et sensibilisation des consommateurs sur les bons gestes.
Mettre en place au moins deux actions directes de valorisation des produits non désirés par les consommateurs :
remise en vente, dons aux associations, reconditionnement, revente à des destockeurs…
Conduire des actions de réduction des suremballages et de réduction du taux de vide dans l’objectif de le limiter à 40 %, en moyenne :
supprimer autant que possible les suremballages et les espaces de vide,
sensibiliser les vendeurs tiers,
effectuer des démarches collaboratives avec les fournisseurs ou les prestataires.
Améliorer la nature et l’utilisation des emballages en :
incorporant une proportion significative de matière recyclée (au moins 75 %),
expérimenter des solutions de réemploi/réutilisation des emballages.
S’assurer que les activités d’entreposage aient une performance environnementale systématiquement attestée par une certification.
Favoriser le développement de modes de livraison décarbonés.
Regrouper systématiquement l’expédition des produits quand c’est possible, sauf demande expresse du consommateur.
Véronique Louwagie, ministre déléguée chargée du Commerce, rappelle que ces « objectifs concrets et mesurables […] feront l’objet d’un suivi par l’État ».
La FEVAD est d’ailleurs prête pour cette mission : « Dans les semaines et mois à venir, la Fevad restera pleinement mobilisée pour promouvoir cette Charte et assurer le suivi des engagements. Elle entend également poursuivre activement le dialogue avec les pouvoirs publics sur les politiques liées à la transition écologique dans le secteur du e-commerce ». On espère que des communications seront faites sur les indicateurs autour de ces engagements.
Les banques rivalisent parfois « d’ingéniosité » pour prélever des frais indus ou des commissions d’intervention non réglementaires, sans oublier une information au public et aux clients parfois incomplète. C’est en tout cas le triste bilan de la DGCCRF sur les établissements bancaires.
Les frais bancaires peuvent être de diverses natures. La Banque de France rappelle qu’il s’agit des « sommes facturées par un établissement bancaire pour le fonctionnement des comptes bancaires de ses clients, que ce soit pour les opérations ou services fournis ou encore pour la gestion des irrégularités enregistrées sur les comptes ».
17 % des établissements en anomalie
La Direction générale de la concurrence, de la consommation et de la répression des fraudes (DGCCRF) se penche sur la seconde catégorie de ces frais. Elle a pour cela contrôlé une centaine d’établissements entre janvier 2023 et mars 2024 : « 17 professionnels se sont révélés en anomalie et des contournements de la réglementation ont été constatés. 12 avertissements, 6 procès-verbaux pénaux et administratifs ont été établis ».
Les manquements prennent plusieurs formes. La plus surprenante consiste certainement en des commissions d’intervention pour des irrégularités sur le compte, alors… « qu’aucune irrégularité de fonctionnement n’apparaissait sur le compte bancaire ».
Les commissions d’intervention sont plafonnées… « Ha bon ? »
Vient ensuite le non respect des plafonds des commissions d’intervention. La Banque de France rappelle qu’ils sont de 8 euros par opération dans la limite de 80 euros par mois avec une offre bancaire classique, contre respectivement 4 et 20 euros pour une offre spécifique « clientèle fragile ».
Problème, note la DGCCRF : « certains établissements ne respectent pas ce plafonnement (facturations d’autres frais …) ». Des banques n’hésitent visiblement pas à empiler les couches : « plusieurs établissements facturaient les commissions d’intervention en plus des forfaits rejets de chèque ou de prélèvement, alors qu’elles doivent y être incluses ».
Autre grief : l’absence de mise à disposition auprès des clients et du public du « document d’information tarifaire », pourtant obligatoire depuis août 2019. Signalons aussi l’utilisation d’un numéro surtaxé pour accéder au service client, une anomalie rectifiée par les banques.
Dans tous les cas, on ne peut que vous conseiller de vérifier régulièrement vos comptes, d’autant plus en cette période de fuite de données importantes, y compris pour des données bancaires.
Numéro surtaxé pour le service client : c’est interdit par la loi
Comme le rappelle le ministère de l’Économie et des Finances, la loi est claire : elle « interdit l’utilisation d’un numéro surtaxé pour « recueillir l’appel d’un consommateur en vue d’obtenir la bonne exécution d’un contrat conclu avec un professionnel ou le traitement d’une réclamation ». Autrement dit, le « service clients » ou « après vente » doit être accessible au consommateur sans devoir recourir à un numéro surtaxé ».
Il y a par contre quelques bonnes nouvelles, notamment une communication « globalement satisfaisante » sur les informations transmises aux clients concernant les offres groupées. Dans l’ensemble, les banques ont « bien respecté leurs engagements tarifaires (gel des tarifs bancaires 2023 pour certains services courants telle que la carte de paiement) », même si une banque avait décidé d’augmenter d’un euro les virements non SEPA. Les clients lésés ont été remboursés, la brochure tarifaire mise à jour.
Un comparateur gratuit du ministère de l’Économie
Il n’est pas toujours facile de s’y retrouver dans toutes les subtilités des conditions tarifaires des banques (en ligne), comme nous avions pu le voir dans notre comparatif (en 2017) de seize d’entre elles.
Notez que le ministère de l’Économie et des Finances propose un comparateur gratuit des « frais facturés par les différents établissements bancaires ». Il faut choisir un département et une liste de critères que vous souhaitez comparer.
Consultez attentivement les documents d’information tarifaire !
N’hésitez pas à consulter les Documents d’information tarifaire (le fameux DIT). Comme le rappelait le ministre de l’Économie en 2020, « la forme et le contenu du DIT ont une normalisation européenne. Le DIT reprend et complète l’extrait standard des tarifs (EST) ».
Vous pouvez, par exemple, consulter celle de Boursorama, du Crédit Mutuel, de Fortuneo ou d’Hello bank!… Les informations y sont standardisées, permettant plus facilement de comparer les offres sur les « les frais d’utilisation des principaux services liés à un compte de paiement ». On y retrouve notamment les frais de tenue de compte, de virement, de fourniture d’une carte bancaire, etc.
Fidèle à leur habitude, nos confrères ont joué du tournevis sur le nouveau membre de la famille d’Apple. Commençons par la fin : le smartphone « d’entrée de gamme » obtient provisoirement (en attendant la disponibilité des pièces détachées) 7/10 en réparabilité, la même note que l’iPhone 16.
Dans les grandes lignes, iFixit note une « nouvelle génération d’adhésif facile à détacher sous la batterie », le même adhésif « à libération électrique » que sur les iPhone 16 et 16 Plus. Il suffit de faire passer un courant entre deux bornes pour libérer la batterie.
Avec l’absence de MagSafe, et donc d’aimant pour bien positionner le chargeur sans fil, iFixit note une perte parfois importante de l’efficacité de la charge. Du côté du port USB Type-C, iFixit se réjouit qu’Apple propose enfin un manuel de réparation officiel.
Ce démontage est également l’occasion d’en découvrir davantage sur les entrailles du smartphone et notamment d’avoir un aperçu du nouveau modem C1 maison, qui remplace le SDX71M de Qualcomm. Pendant plusieurs années, les deux partenaires se sont écharpés devant les tribunaux.
C’est une barre symbolique qui a été dépassée le 2 mars à 15 h, avec 40 271 225 joueurs très exactement. Les 39 millions avaient été dépassés en décembre. « Depuis un certain temps déjà, il ne faut attendre que quelques mois pour que Steam ajoute un million d’utilisateurs simultanés », explique Neowin.
Le cap des 20 millions de joueurs simultanés était tombé en mars 2020 pendant le début de l’épidémie de Covid-19. Pour arriver aux 30 millions, il a fallu attendre 2022. SteamDB propose un historique sur près de deux décennies.
En tête du classement, on retrouve sans surprise Counter-Strike 2, tandis que la seconde place est occupée par Monster Hunter Wilds, un jeu sorti le 28 février et qui réunit encore aujourd’hui plus de 1,2 million de joueurs. Le titre a même dépassé les 1,3 million ce week-end.
Selon le site (non officiel SteamDB), Monster Hunter Wilds se classe 5ᵉ des titres les plus joués de « tous les temps » sur Steam, avec un pic à 1,384 millions. Devant, on retrouve Counter-Strike 2 avec 1,818 million, Palworld avec 2,101 millions, Black Myth: Wukong à 2,415 millions et PUBG: Battlegrounds en tête avec 3,257 millions.
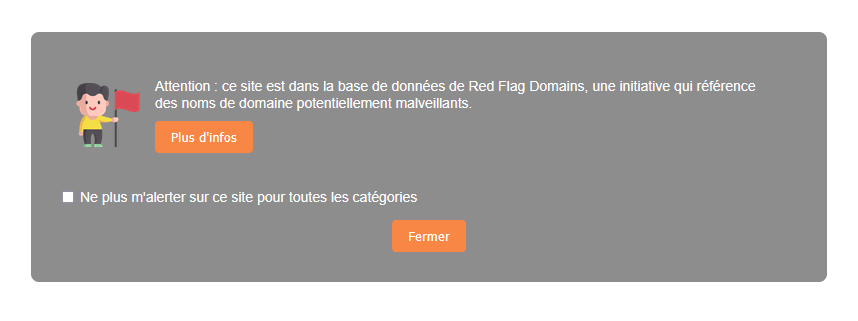
Notre extension pour les navigateurs Chrome et Firefox intègre désormais des listes externes. En plus des médias générés par IA (GenAI), elle vous alerte désormais lorsque vous visitez des noms de domaines figurant dans les bases de Red Flag Domains ou de l’Autorité des marchés financiers. De quoi vous éviter de potentielles arnaques !
Mise à jour du 6 mars : une version 2.0.3 a été mise en ligne, aussi bien sur Chrome (et les dérivés Chromium) que sur Firefox. Il s’agit principalement de corriger des bugs mineurs, de mettre à jour la liste blanche et d’atteindre le palier des 3 000 « sites d’informations » dont les articles ont été, « en tout ou partie », générés par IA.
Au fil des semaines, la liste a continué de s’enrichir, dépassant allégrement les 1 500 puis les 2 000 et maintenant 3 000 domaines… et ce n’est pas fini ! En plus de nouvelles listes, nous avons ajouté une mise à jour automatique de la liste dans la version 2.0 de notre extension.
Depuis le début, nous avons fait le choix de rendre cette extension accessible à tout le monde gratuitement, mais rappelons qu’elle est financée grâce à nos abonnés : merci à eux ! Pour lire l’ensemble de nos contenus, participer aux débats et nous soutenir, abonnez-vous !
Nous ne sommes pas les seuls. Yann Gaudin, un ancien conseiller-formateur de France Travail devenu lanceur d’alerte, s’étonnait de découvrir dans Google Actualités un article concernant son activité, en y étant cité… sans avoir donné d’interview ni même disposer des données mentionnées dans l’article. Ce site était bien signalé par notre extension, comme lui répondaient Jean-Marc et notre confrère Marc Rees.
Une recherche Google Actualités montre qu’en fait ce sont pas moins de troisarticlesGenAI qui lui ont été consacrés depuis un mois – eux aussi signalés par notre extension –, plagiant (jusque dans leurs titres) un article paru sur Capital en octobre dernier (mais sans le mentionner).
En outre, l’article ayant fait réagir Yann Gaudin indiquait qu’il était lui-même inspiré de celui publié sur les Déchargeurs, tout en y rajoutant des chiffres et témoignages fictifs… preuve supplémentaire que les articles GenAI peuvent « halluciner » des informations qui n’existent pas, comme nous le relevions par ailleurs dans notre enquête sur cette « rumeur » générée par IA, mais relayée par de nombreux médias.
L’avocat spécialiste du numérique Alexandre Archambault qualifiait notre extension de « super boulot », suggérant qu’elle pourrait aussi gérer des sites arnaques… et c’était effectivement un travail en préparation chez Next. C’est d’ailleurs l’objet de la principale nouveauté de cette version 2.0 de notre extension : la gestion de listes multiples, au-delà des médias utilisant de l’IA générative.
Pour commencer, nous en avons ajouté deux listes :
Red Flag Domains : de nouveaux domaines ajoutés chaque jour
« Les Red Flag Domains sont des listes de noms de domaine très récemment enregistrés, probablement malveillants, dans les TLD français », explique Nicolas Pawlak, créateur du site. Il s’occupe également de vérifier et valider les liens à la main avant de les ajouter à la liste.
Une liste précieuse puisqu’elle comprend généralement des noms de domaine pouvant servir à du phishing, en essayant de se faire passer pour des sites légitimes. Être alerté peut donc éviter de se faire arnaquer.
L’extension récupère automatiquement la dernière liste disponible sur Red Flag Domains et se met à jour régulièrement pour être certain de ne rien louper. Les données sont publiées sous licence Creative Commons BY-NC-SA 4.0 par Red Flag Domains.
Voici, par exemple, les derniers ajouts dans la liste. Il suffit de lire les noms de domaine pour comprendre les risques : booking-com[.fr], virements-creditmutuel[.fr], macommande-leboncoin[.fr], mondialrelay-locker[.fr], assembleee-nationale[.fr], etc.
Liste noire de l’Autorité des marchés financiers
La seconde liste est celle des « entités non autorisées à proposer des produits ou services financiers en France […] Les acteurs figurant sur les listes noires, ayant fait l’objet d’une mise en garde publiée par l’Autorité des marchés financiers (AMF) et/ou usurpant l’identité d’un acteur régulé », explique l’AMF.
Pour le moment, nous récupérons cette liste afin de la nettoyer pour que l’extension puisse l’utiliser. Nous travaillons à une mise à jour qui pourrait automatiquement récupérer la liste depuis data.gouv.fr et la préparer pour l’extension. Les données sont publiées sous Open Licence 2.0 par le gouvernement.
Revenons à notre extension. Par défaut, les trois listes – GenAI, Red Flag Domains et AMF – sont activées après l’installation. Aussi bien sur Chrome que Firefox, il y a une page Options permettant d’activer ou désactiver certaines listes.
Pour y accéder sur Firefox, commencez par effectuer un clic droit sur l’icône de l’extension, puis sur Gérer l’extension. Sur cette page, cliquez sur les « … » puis Options pour arriver sur la page de gestion. Sur Chrome, un clic droit sur l’icône de l’extension propose directement un lien vers Options de l’extension.
En plus d’activer ou désactiver des listes, vous pouvez également voir le nombre d’éléments de chaque liste et la date de dernière mise à jour (de la liste dans l’extension). Un bouton permet de mettre à jour toutes les listes si besoin, sinon la mise à jour est automatiquement faite à intervalles réguliers.
Vous pouvez évidemment utiliser l’extension sans jamais vous rendre dans les options, les trois listes sont alors activées et mises à jour automatiquement. C’est d’ailleurs l’utilisation que l’on vous recommande.
À vous les studios lecteurs !
Nous n’avons pour le moment intégré que trois listes, mais notre extension n’est pas limitée à ce nombre et il est possible d’en ajouter facilement. Si vous avez des propositions de listes à ajouter, n’hésitez pas à nous le signaler via les commentaires.
La publication du code source interviendra rapidement sur le dépôt GitHub de Next.


![[Édito] Mort et zombification des sites de hardware](https://next.ink/wp-content/uploads/2025/03/Hardware.webp)




















![[MàJ] Orange lance un forfait 5G+ pour le grand public avec une « bande passante dédiée »](https://next.ink/wp-content/uploads/2024/04/5g.webp)